“차장님. 저희가 지금까지 수치형 데이터를 살펴봤잖아요. 범주형 데이터는 분석 방법이 다른가요?”
“그럼요. 지금까지는 연봉, 인원수와 같은 연속적인 숫자가 있는 수치형 데이터를 다뤘지만, ‘선호하는 프로그래밍 언어’, 업무 형태’, ‘학습 희망하는 언어’와 같은 칼럼은 모두 범주형 데이터였죠. 범주형 데이터는 수치형 데이터와는 분석 방법도, 시각화 과정도 달라요. 말이 나온 김에 범주형 데이터 분석도 시작해 볼까요?”
박차장 범주형 데이터를 분석할 때는 먼저 각 항목의 빈도수를 파악해야 해요. 어떤 항목이 더 자주 나타나는지, 어떤 패턴이 있는지 살펴볼 수 있죠. 또, 수치형 데이터와 결합해 항목별로 어떤 차이가 있는지 분석할 수도 있어요.
김대리 수치형 데이터를 분석할 때는 정규분포를 따르는지, 데이터 변환이 필요한지, 이상치는 없는지를 먼저 확인했었는데, 범주형 데이터는 확실히 시작부터 다르네요.
박차장 방법은 다르지만 목적은 같아요.
김대리 데이터를 파악하기 위한 거죠?
박차장 맞아요. 그럼 바로 범주형 데이터의 통계량부터 살펴볼까요?
[첨부 파일: 13_이상치제거데이터.xlsx] 다운로드
전체 범주형 데이터에 대한 통계 결과는 다음과 같습니다.
- 업무 형태 - 값 개수: 3254 - 유니크 값 개수: 8 - 가장 흔한 값(top): 풀타임으로 일합니다. - 빈도수(freq): 1742
- 업무 - 값 개수: 3254 - 유니크 값 개수: 25 - 가장 흔한 값(top): 백엔드(서버) - 빈도수(freq): 606
(중략)
- 도서 구매 성향 - 값 개수: 3254 - 유니크 값 개수: 5 - 가장 흔한 값(top): 업무나 프로젝트 등 필요한 상황이 오면 그때그때 구매하는 편이다.(비교적 적극적으로...) - 빈도수(freq): 1751
- 선호하는 한 회사 내 근무 연수 - 값 개수: 3254 - 유니크 값 개수: 8 - 가장 흔한 값(top): 2~3년 - 빈도수(freq): 1197 |
김대리 범주형 데이터가 꽤 많네요. 값 개수, 유니크 값, 가장 흔한 값, 빈도수를 통곗값으로 구했어요. 수치형 데이터의 통계량과는 다르네요.
박차장 그렇죠? 각 통곗값이 무엇을 의미하는지 알아볼게요. ‘값 개수’는 말 그대로 데이터 개수를 말해요. 결측값을 제거해서 3254개로 모두 동일하네요. ‘유니크 값Unique Value’은 고유한 범주, 즉 항목의 종류라고 생각하면 됩니다. ‘가장 흔한 값’은 빈도수가 가장 높은 항목을 말해요. ‘빈도수’는 가장 높은 빈도수의 항목의 데이터 개수고요.
김대리 낯설어서 그런지 눈에 잘 들어오지 않아요.
박차장 시각화를 이용하면 데이터를 더 쉽게 파악할 수 있어요. ‘업무’와 ‘업무 형태’를 그래프로 그려 볼까요? 막대그래프와 원그래프 두 종류로 살펴볼게요
다음은 범주형 데이터인 ‘업무’와 ‘업무 형태’를 막대그래프로 그린 결과입니다 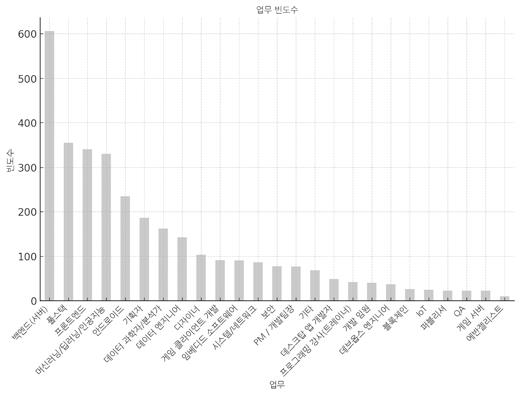 ‘업무’ 막대그래프 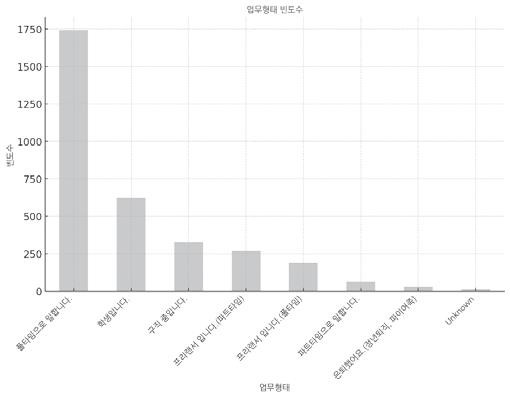 ‘업무 형태’ 막대그래프 |
다음은 범주형 데이터인 ‘업무 형태’를 원그래프로 그린 결과입니다 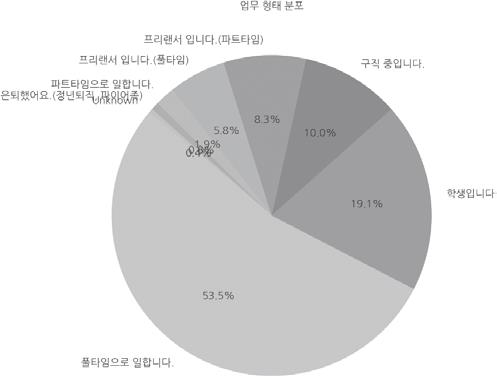 |
김대리 확실히 그래프가 보기 편해서 좋아요. 학원에는 재직자의 비중이 높네요.
박차장 막대그래프나 원그래프는 특정 범주가 얼마나 자주 등장하는지 쉽게 이해할 수 있어요. 또 다른 시각화 도구로 히트맵Heatmap을 이용하면 여러 개의 범주형 데이터도 한 번에 파악할 수 있죠.
다음은 ‘업무 형태’와 ‘재직 회사 산업군’의 조합에 따른 빈도수를 히트맵으로 그린 결과입니다 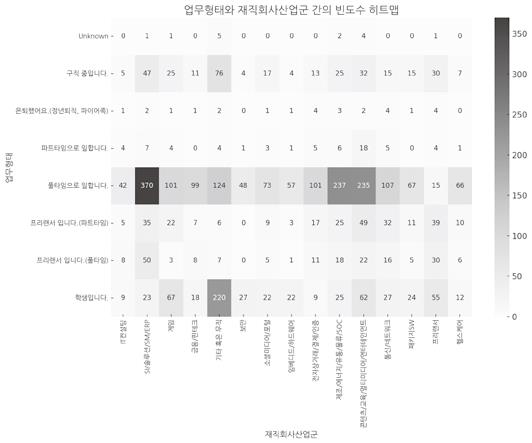 |
김대리 그래프상으로 ‘업무 형태’는 풀타임 근무가 가장 많고, 그 다음 학생을 포함한 구직자가 많아요. 추가로 프리랜서들은 주로 SI/솔루션쪽 IT산업에 있다는 것을 알 수 있네요. 데이터의 크기를 색으로 표현하니 비교하기가 훨씬 수월하네요.
박차장 맞아요. 데이터의 분석 목적에 따라 적합한 그래프를 찾는 것도 중요합니다.
박차장 범주형 데이터는 각 항목별로 다른 수치형 데이터와 결합해서 분석할 수 있어요. ‘업무 형태’별로 ‘연봉’이 어떻게 다른지 막대그래프로 파악해 볼까요?
‘업무 형태’별 ‘연봉’ 평균을 그린 막대그래프입니다 각 업무 형태의 평균 연봉을 시각적으로 비교할 수 있습니다. 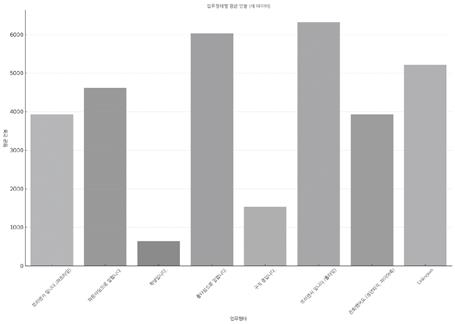 |
박차장 x축은 업무 형태, y축은 각 항목의 평균 연봉이에요. 연봉이 가장 높은 순서는 풀타임 프리랜서 → 풀타임 → 파트타임순이네요. 풀타임은 정규직 근무라고 볼 수도 있겠어요.
김대리 그렇다면 프리랜서 중 풀타임 근무자는 정규직보다 연봉이 높지만, 파트타임 근무자는 그 반대인 거네요. 같은 프리랜서여도 풀타임과 파트타임은 일하는 시간에 차이가 있을 수 있으니 가능하면 시간당 급여로 환산해 보면 좋겠어요.
박차장 그러네요. 범주형 데이터를 하나 더 추가해서 시각화해 볼게요. ‘오픈소스 활용 여부’를 활용하면 어떨까요? 단, 데이터가 없는 것과 마찬가지인 Not specified는 제외할게요.
여기 “Not specified” 데이터를 제외하고 업무 형태별 오픈소스 활용 여부에 따른 평균 연봉을 비교한 막대그래프입니다. 각 업무 형태에서 오픈소스를 활용 여부에 따라 평균 연봉을 시각적으로 비교할 수 있습니다. 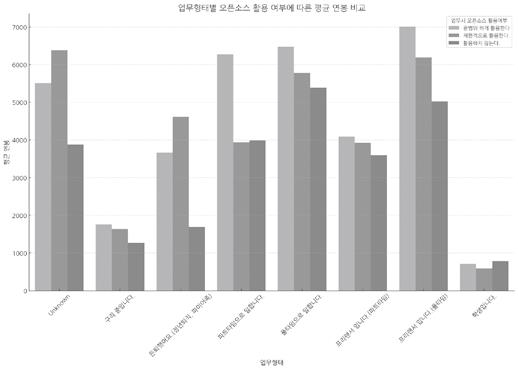 |
박차장 막대그래프가 익숙하긴 하지만 ‘오픈소스 활용 여부’만 3가지로 구분되니 색깔을 유의해서 봐야 해요. 이 경우에는 히트맵이나 그래프를 분할해서 박스 플롯을 보는 방법도 좋겠어요. 결과가 어떤가요?
김대리 오픈소스를 사용하는 사람들의 평균 연봉이 더 높아요. 그렇다면 오픈소스를 활용해야 연봉이 더 높다고 결론을 낼 수 있을까요?
박차장 그건 좀 위험한 결론이 될 수 있어요. 우리가 이 데이터에서 파악할 수 있는 건 두 관계 중 하나가 바뀌면 한쪽도 따라 바뀌는 상관관계예요. 원인과 결과를 파악하는 인과 관계가 아니기 때문에 이 데이터만으로 오픈소스를 활용하면 연봉이 높다는 가설을 설명하기가 어려워요. 그보다 특정 직무에서 오픈소스 활용도가 높고, 그 직무의 연봉이 높다고 볼 수 있을 것 같아요.
김대리 그러네요. 아니면 자기 계발 의지가 높은 사람이 오픈소스를 많이 활용하고, 연봉이 높은 건 아닐까요? 여러 가지 결론을 도출할 수 있어서 섣불리 결론을 내긴 어렵겠네요. 이 부분은 데이터를 더 분석해 봐야 알 수 있겠어요.
박차장 그렇다면 수치형 데이터인 ‘개발 경력’을 하나 더 추가해서 살펴볼게요. 칼럼이 3개이니 좀 더 시각적으로 보기 편하도록 추세선도 추가할게요.
여기 ‘오픈소스 활용 여부’에 따른 ‘개발 경력’과 ‘연봉’의 관계를 나타낸 선그래프와 함께 추세선을 추가한 그래프입니다. 각 개발 경력과 오픈소스 활용 여부에 따른 평균 연봉의 변화를 추세선과 함께 시각적으로 비교할 수 있습니다 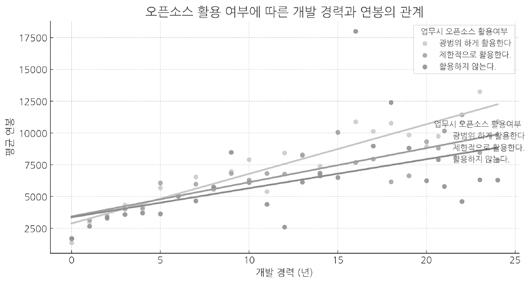 |
박차장 산점도에 추세선을 추가했어요. 이제 개발 경력에 따라 평균 연봉이 어떻게 달라지는지 확인할 수 있어요.
김대리 개발 경력이 높을수록 연봉이 높네요. ‘오픈소스 활용 여부’는 다른 변수와의 상관관계를 더 살펴보면 좋겠어요.
박차장 맞아요. 결과가 왜 이렇게 나왔을까 생각하는 습관을 들이면 분석하는 데 많은 도움이 돼요.

시장 조사, 고객 분석, 매출 예측, 보고서를 한 번에
코드 한 줄, 수식 계산 없이 기초 통계부터 고급 데이터 분석까지!
이 책은 데이터 분석을 경험해 본 적이 없는 사람 또는 데이터 분석에 AI를 적용하려는 사람을 위해 AI를 활용한 데이터 분석의 전 과정을 쉽게 익힐 수 있도록 구성했습니다. 단순히 데이터 분석 과정을 훑는 것이 아니라 실무에서 데이터 분석 프로젝트가 어떻게 시작되고 마무리되는지 체감할 수 있도록 데이터 분석을 시작하는 ‘김대리’와 ‘박차장’이라는 인물을 활용했습니다. 이제 막 데이터 분석을 시작해 데이터의 개념, 챗GPT 사용법부터 고급 데이터 분석과 시각화까지 한 단계씩 나아가는 김대리를 통해 실무에서 흔히 마주치는 데이터 분석 문제를 살펴볼 수 있습니다. 이 과정에서 여러분은 실무에 바로 적용 가능한 지식과 기술을 습득할 수 있는 것은 물론이고 실제 분석 과정에서 자주 부딪치는 문제를 해결하는 방법도 알 수 있습니다.
더불어 누구나 이 책에서 다루는 모든 프로젝트를 직접 실습할 수 있도록 데이터 파일을 제공합니다.
누구나 프로처럼,
나만의 데이터 분석가를 월 20달러로 고용하는 방법
챗GPT는 누가 어떻게 쓰느냐에 따라 무궁무진한 가능성을 가진 도구입니다. 때로는 SNS 콘텐츠를 뽑는 유능한 콘텐츠 기획자였다가, 의뢰인의 상담을 도와주는 변호사면서 막힘 없이 데이터 분석 주제 제안부터 보고서 작성까지 깔끔하게 정리해 주는 똑똑한 분석가가 되기도 합니다. 이 모든 역량을 가진 뛰어난 파트너를 챗GPT라는 하나의 도구로 고용하는 방법을 알려드립니다.
이전 글 : [시작! AWS] 폐쇄 네트워크와 AWS 엔터프라이즈 아키텍처
다음 글 : 챗GPT만 활용해서 유시민 작가처럼 글쓰기
최신 콘텐츠