IT/모바일
Apache Arrow는 다중 언어, 이종 데이터 인프라를 사용 가능하게 합니다.
우리는 데이터 분석시대의 황금기에 살고 있습니다. 데이터는 어느 때보다 많아졌고, 이 데이터를 활용하는 기업체는 상업적 가치를 만들어 낼 수 있는 기회를 끝도 없이 맞이하고 있습니다. 오픈소스 진영의 빅 데이터 기술 기업은 전 방위에 걸쳐서 이러한 사례를 만들어 내고 있고, 이러한 기업들은 서로 다른 데이터 스토리지(Apache HDFS, HBase, MongoDB, Elasticsearch, Apache Kudu 등), 분석 엔진(예를 들면, Apache Spark, Drill, Impala등과 같이요.)을 사용하고 있습니다. 게다가 서로 다른 분석 언어(SQL, Python/Pandas, R, Java 등)를 사용합니다.
서로 다른 데이터 인프라는 서로 간의 데이터 공유를 위해서 많은 작업을 필요로 합니다. 일반적으로는 두 가지 방식으로 이루어질 수 있습니다.
- API방식. 서로 다른 시스템은 API를 통해서 데이터를 공유 할 수 있습니다. 예를 들어, Drill에서 HBase API를 활용하여 데이터 레코드를 읽어오고, Spark는 Kafka API를 사용해서 데이터를 읽어오는 것처럼 말입니다.
- File방식. 서로 다른 시스템은 동일한 포맷의 파일로 분석 처리 과정을 최적화 할 수 있습니다. 예를 들어, 많은 기업들이 Spark를 통해서 데이터 전처리 과정과 분석에 사용합니다. 그리고 나서 SQL 엔진인 Drill이나 Implala를 통해서 BI 도구에 사용하여 비즈니스 분석을 할 수 있도록 사용하는 것이죠.
많은 API들이 데이터의 실시간 이동을 지원하는 동안, 이 방식은 몇 가지 문제점을 맞닥뜨리게 됩니다. 첫 번째는, 직렬화와 역 직렬화의 오버헤드가 너무 높다는 것이고, 이 문제점이 애플리케이션 성능의 병목을 초래한다는 점입니다. 두 번째로 데이터를 표현할 표준이 없기 때문에, 시스템을 개발하는 개발자는 반드시 다른 시스템들과의 통합을 위한 통일된 기준을 매번 수립해야 합니다.
그러는 동안 빅 데이터 생태계에 사실상의 표준으로 Parquet 파일 포맷이 최근 몇 년간 광범위하게 사용되게 되었습니다. Parquet 파일은 자기 기술적(self-describing)이며, 데이터는 컬럼 방식을 가지고 있어서 훌륭한 표현력과 데이터 분석에서 뛰어난 성능을 보여줍니다. 분석 작업을 할 때에는 사용자는 단지 Parquet 방식으로 기술된 데이터 셋에서 필요한 컬럼만 읽어오게 할 수 있습니다.
Parquet의 성공을 기반으로, 이름 있는 오픈소스 프로젝트의 maintainer들은 스토리지, 데이터 처리, 분석에 집중하기 시작했습니다. (Drill, Impala, Cassandra, Kudu, Spark, Parquet 등이 좋은 예이다.) 최근에는 Apache Arrow인 인메모리 컬럼 데이터 스토리지와 분석 프로젝트가 공개되었습니다. Arrow는 메모리 상에서 컬럼 구조로 데이터를 구성할 수 있고, 해당 데이터를 사용할 수 있는 라이브러리를 제공합니다. Arrow 포맷은 CPU 캐시 로컬리티 특성을 극대화 할 수 있고, SIMD 명령어같이 인텔 CPU를 벡터화 해서 활용할 수 있는 기능을 제공합니다.
Arrow는 이제 다양한 시스템과 프로그래밍 언어에 적용이 되고 있습니다. 또한 서로 다른 데이터 인프라에 대하여 차세대 기반을 제공할 계획이죠. Arrow 덕분에 이전에 커버하지 못했던 모든 사례에 대하여 적용할 수는 없지만, 3가지 대표적인 사례에 대하여 살펴보면:
R과 파이썬에서 data frame의 빠른 import, export. Pandas 라이브러리의 창시자인 Wes Mckinney와 Arrow의 초기 커미터, RStudio의 수석 엔지니어인 Hadley Wickham는 Arrow의 기능을 Python과 R에서 사용할 수 있도록 Python과 R에 대하여 Arrow C++ 라이브러리를 바인딩 시켰다. 현재는 1차원 스키마만 지원을 하지만, 향후에는 중첩된 스키마도 API를 통해서 쉽게 사용할 수 있도록 지원 할 예정입니다. Python과 R 개발자들은 data frame을 Arrow (또는 Feather로 알려진 파일 구조)로 쉽게 내보낼 수 있습니다. 이런 기능은 단순하게 write_dataframe 와 read_dataframe 함수 호출을 통해서 수행할 수 있습니다.
|
library(feather) path <- "file.feather" write_feather(df, path) df <- read_feather(path) |
import feather path = 'file.feather' feather.write_dataframe(df, path) df = feather.read_dataframe(path) |
더 많은 정보를 원하시면 다음의 페이지를 참고하세요:
- https://blog.rstudio.org/2016/03/29/feather/
- http://blog.revolutionanalytics.com/2016/05/feather-package.html
- http://wesmckinney.com/blog/feather-its-the-metadata/
고성능 Parquet 리더. Parquet은 이제 사실상 빅 데이터 진영의 파일 포맷의 표준이 되었습니다. 예를 들어, Parquet은 Impala, Drill, Spark SQL에서 기본 포맷이고, 대부분의 하둡 유저들이 Parquet 포맷에서 데이터를 사용하고, 많은 시스템에서 Parquet 파일 구조를 지원합니다. Parquet과 Arrow 커뮤니티는 고성능 Parquet-to-Arrow reader의 제공을 위해서 연합하였습니다. 이러한 현상은 이제 parquet 파일이 이전과는 비교할 수 없을 만큼 빠른 속도를 제공할 수 있게 되었습니다. 게다가, 고수준 언어인 파이썬과 R에서도 Parquet에서 고수준의 지원을 시작했습니다. 이 Parquet 리더는 중첩 데이터 유형도 포함하여 전체 Parquet을 지원할 예정입니다. 현재 상황은 벡터화된 컬럼 데이터를 parquet-cpp 를 사용하여 읽을 수 있습니다. flat 스키마는 사용 가능하며, Python에서도 동일한 기능을 제공합니다. 중첩된 데이터의 지원은 C++과 자바 모두 현재 진행 중에 있습니다.
빅 데이터 생태계에서 Python, R, 자바스크립트의 고수준 지원. 고수준 언어인 Python, R, 자바스크립트는 개발자와 데이터 과학자들 사이에서 눈부신 관심을 받고 있습니다. 왜냐하면 이들은 정말 개발자를 생산적으로 바꿔주기 때문입니다. 하지만, 빅 데이터와 분산 연산에서만큼은 이들은 아직 비주류라고 할 수 있습니다. 예를 들어, Python 기반의 Spark 애플리케이션은 Java/Scala 기반의 Spark 애플리케이션보다 눈에 띄게 느립니다. Arrow는 이 부분을 해결할 수 있습니다. 예를 들어 SQL 쿼리를 Python UDFs에서 활용하면, 매우 높은 수준의 성능을 기대할 수 있습니다. 게다가 이들 UDFs는 다른 쿼리 엔진에서도 활용이 가능합니다. 아키텍처에서 보면 사용자 정의된 Python 코드는 Arrow record를 다음 다이어그램과 같이 배치 방식으로 실행시키게 됩니다.
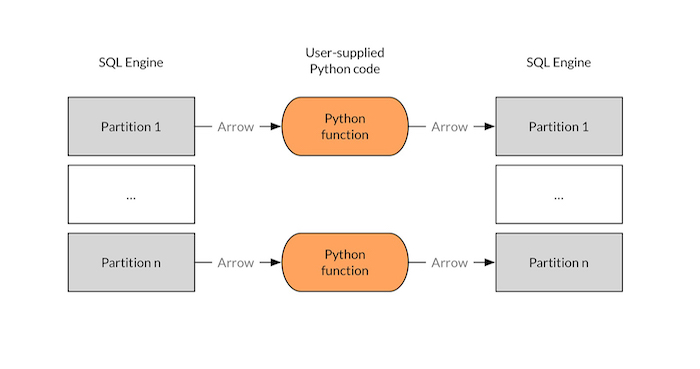
Figure 1. Jacques Nadeau의 다이어그램
물론 이들은 Apache Arrow 덕분에 곧 가능해질 몇 개의 예제에 지나지 않습니다. 인메모리 방식의 데이터 표현 방식이 산업계 표준이 되는 순간에는 다른 데이터 환경간의 통신의 기반을 담당할 것입니다. 15개 이상의 빅 데이터 기술 기업들이 이미 이 대열에 동참하였습니다. 모든 업계가 Arrow로 세상의 거의 대부분의 데이터를 주무를 일이 얼마 남지 않습니다. 여러분이 Arrow를 직접 사용하지 않을지라도, 언젠가는 알게 될 것입니다. Python으로 SQL 구문을 실행할 때, 혹은 서로 다른 데이터베이스에서 레코드를 조인할 때의 속도로 조인을 할 때, 혹은 다양한 사례를 Arrow가 해결할 수 있을 것입니다. Arrow IPC 메커니즘은 현재 진행형이지만, 서로 다른 언어간의 통신을 가능하게 하고, 공유 메모리와 제로 카피 데이터 엑세스는 오버헤드를 줄이고 서로 다른 시스템간의 UDFs를 가능하게 할 것입니다.
*****
원문 : Analysis without boundaries
번역 : 김준호
이전 글 : 이제는 디자인 패턴을 배울 5가지 이유

최신 콘텐츠