과거의 인공지능이 쫄쫄 흐르는 약수물과 같았다면, 지금의 인공지능은 마구 쏟아지는 폭포수가 떠오를 정도로 엄청난 발전과 파급 효과를 낳고 있다. 많은 전문가들이 올 2024년에는 인공지능 기술과 산업이 폭발적으로 발전하는 모습을 보게 될 것이라고 예측하고 있다. 작년 챗 GPT를 처음 접하고 이거 꽤 쓸만한데 했는데, 어느새 AI 기능이 스마트폰에 기본 탑재가 되어 버렸다.
암울한 것은 인공지능으로 인해, 많은 예술 창작자들 뿐만 아니라, 나름 견고한 위치에 있다고 여겨져왔던 개발자의 밥줄도 위협을 받고 있는 상황이다. 많은 초급 개발자들이 직장을 잃고 있다고 한다. 인공지능에 먹히지 않고 조금이라도 오래 개발자로 살아 남기 위해서는 보다 전문적인 인공지능 지식은 필수인 것이다.

'밑바닥부터 시작하는 딥러닝 4'은 그러한 인공지능 지식과 기술을 쌓는데, 참 도움이 되는 책이다. '밑바닥부터 시작하는 딥러닝' 시리즈는 역자의 설명을 보면, 총 5편으로 구성된다고 한다. 최근 나온 것이 4편이고 5편은 앞으로 나올 예정이다. 1편에서는 CNN과 이미지 처리, 2편은 RNN과 자연어 처리, 3편은 딥러닝 프레임워크, 그리고 이번 4편은 심층 강화 학습이 핵심 주제다.

심층 강화 학습은 강화 학습과 딥러닝이 결합된 분야다. 강화 학습은 아이가 손을 사용하고, 걷는 방법을 스스로 익히는 거처럼 하나하나 과정을 가르치는 사람 없이 환경과 상호작용한 데이터를 바탕으로 더 많은 보상을 얻는 방법을 학습하는 것을 말한다.
'밑바닥부터 시작하는 딥러닝 4'는 가장 대중적으로 쓰이는 파이썬을 사용하며, 넘파이, 맷플롯립, 3편에서 나왔던 딥러닝 프레임워크 DeZero, 파이토치, OpenAI Gym 등도 사용한다. 내용은 크게 전반부와 후반부 둘로 나눠지는데, 전반부인 1장부터 6장까지는 강화 학습 기초를 공부하고, 후반부 7장부터 10장까지는 강화 학습 적용과 심층 강화 학습의 미래를 다룬다.

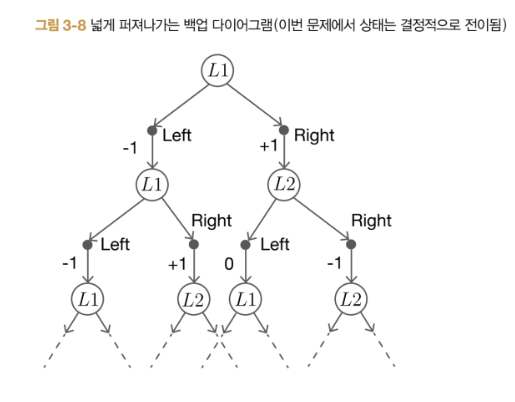
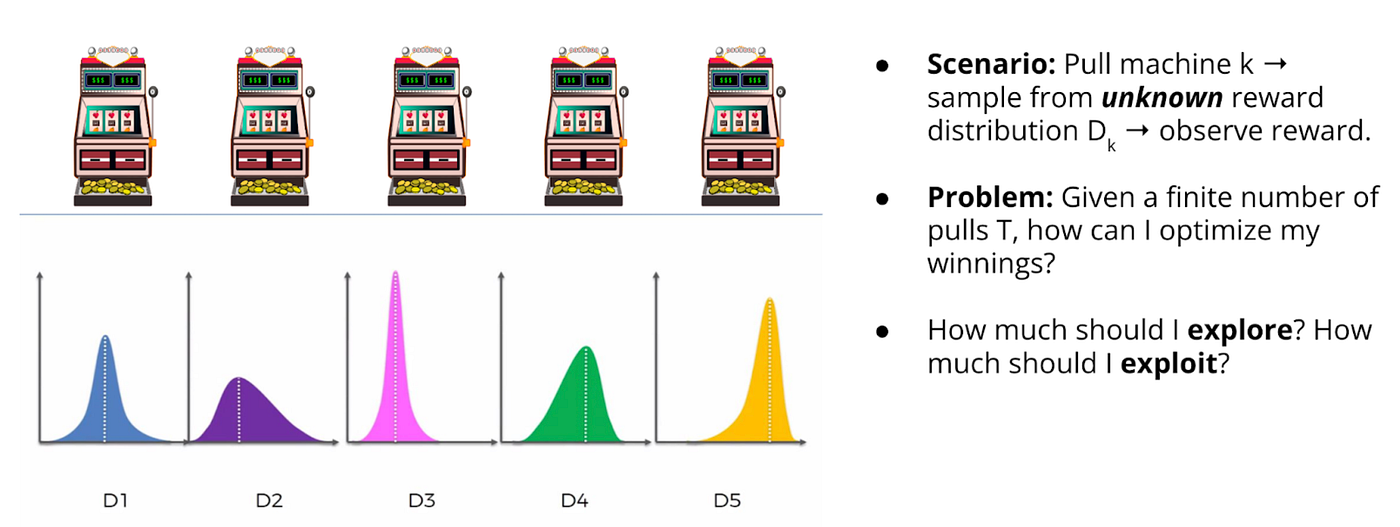
전반부에 등장하는 슬롯머신, 밴디트 문제, 마르코프 결정 과정, 벨만 방정식, 정책 반복법, 몬테카를로법 등은 강화 학습을 처음 공부하는 사람 입장에서는 이름만 봐도 참 어렵게 느껴질 것이다. 그러나 미리 겁먹을 필요는 없다. '밑바닥부터 시작하는 딥러닝 4'라는 책 이름처럼 강화 학습에 관련된 지식을 밑바닥 기초부터 설명하고 있다. 복잡한 개념을 핵심만 잡아 단순화 시킨 그림과 도표, 심플한 예제 코드를 활용해서 이해를 돕고 있다.

특히 인공지능을 공부하는데 큰 걸림돌이 되는 수학적인 부분도 '밑바닥부터 시작하는 딥러닝 4'에서는 그리스 문자 읽는 법까지 알려줘가면서, 식의 의미를 하나하나 알려주며, 풀어가고 있어서 별도의 수학 책이 없어도 이해할 수 있다. 그러나 후반부는 편미분, 벡터 같은 것이 나오다 보니, 책에 있는 설명만으로는 부족함을 느낄 수도 있을 것이다. 그레디언트, 나블라 같은 기호 읽는 법이 빠져 있기도 했다. 그러나 전반적인 의미는 잘 설명 되어 있어 맥락을 이해하는 데는 어렵지 않을 것이다. 어쨌든 이 책 뿐만 아니라, 보다 전문적인 인공지능 책을 보기 위해서는 수학 능력을 갖출 필요는 있다.
내 경우 이전에 나온 '밑바닥부터 시작하는 딥러닝' 시리즈 전부를 본 것이 아니라, 이해하는 데 어렵지 않을까 걱정했는데, 이 책 설명이 쉽게 잘 되어 있는 것도 있고, 전에 봤던 인공지능 서적들을 통해 얻은 단편적인 지식 덕도 있어서 그런지 큰 어려움 없이 볼 수 있었다. 원리 설명, 수학 적 이해, 예제 코드, 이 모든 삼박자가 잘 맞는 책이라 느꼈다.
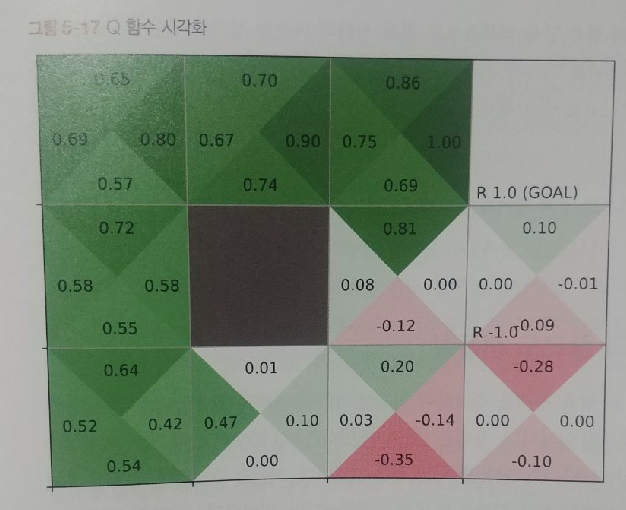
그리고 강화 학습을 잘 모르는 초보일수록 이 책 순서 그대로 공부하는 것을 추천한다. 에이전트, 환경, 행동, 보상, 상태라는 강화 학습의 기본 메커니즘을 항상 염두에 두고 이어지는 인공지능 알고리즘을 학습한다. 후반부에서는 강화 학습에 딥러닝을 추가 결합하게 된다. DeZero로 신경망을 쉽게 구현하여 Q 러닝을 해본다. OpenAI Gym으로 막대의 균형을 잡는 게임도 해보고, DQN으로 경험 재생과 목표 신경망을 더해도 본다. 이처럼 '밑바닥부터 시작하는 딥러닝 4'은 내용이 한 단계 한 단계 강화 학습 지식을 쌓는 점진적 구성으로 되어 있다.

혹, 책을 보다가 내가 왜 이런 걸 배우나 의문점이 든다면, 마지막 10장을 먼저 보는 것도 추천한다. 심층 강화 학습 전체 큰 그림을 볼 수 있고, 각종 활용 분야에 대해서도 알 수 있게 되어, 다시 열공하는데 필요한 학습 동기 부여를 얻을 수 있을 것이다.
이번 '밑바닥부터 시작하는 딥러닝 4'을 통해 막연하고 복잡하게만 생각된 강화 학습 전반을 잘 이해할 수 있었고, 개념도 확실히 잡을 수 있었다. 강화 학습이 자율주행이며, 앞으로 인공지능 시대와 함께할 로봇 기술에도 빼 놓을 수 없는 중요한 AI 기술이라는 것을 알 수 있었다.
강화 학습을 보다 쉽고 제대로 배우고 싶다면, '밑바닥부터 시작하는 딥러닝 4'가 분명 좋은 출발점이 되어 줄 것이다.
















 Author: 사이토 고키 지음 / 개앞맵시 옮김
Author: 사이토 고키 지음 / 개앞맵시 옮김