이 책은 AWS에서 제공하는 AI와 ML 기능을 활용하여 데이터 과학 프로젝트를 구축하고 배포하는 방법을 다룬 실전 지침서다. 아마존 EC2, 아마존 EBS, 아마존 다이나모DB, AWS 람다, AWS IAM을 비롯한 다양한 AWS 서비스를 사용하여 데이터 수집 및 처리, 머신러닝, 보안을 다룬다. 또한 AWS에서 데이터 과학 프로젝트의 비용을 절감하고 성능을 향상시키는 팁도 소개한다. 이 책을 따라 모든 학습을 마치고 나면 머신러닝 모델의 성능을 향상하기 위한 기술과 방법을 이해하고, AWS를 효과적으로 활용하여 머신러닝 모델을 구축하고 배포할 수 있게 될 것이다.
저자소개
저자
크리스 프레글리
AWS 샌프란시스코 지사에서 AI/ML 분야 수석 개발자 애드버킷으로 재직 중이다. 동시에 파이프라인AI(PipelineAI)의 창립자이며, 이전에는 데이터브릭스(Databricks)의 솔루션 엔지니어, 넷플릭스(Netflix)의 소프트웨어 엔지니어로 일한 경력이 있다. 지난 10년간 AI/ML 분야에서 폭넓은 지식을 쌓아오면서 오라일리가 주최하는 AI 관련 시리즈 프로젝트인 ‘AI Superstream Series’에 참여하기도 했다. 또한 세계 각국에서 열리는 AI/ML 콘퍼런스에 참석하여 지식을 나누는 연설을 정기적으로 하고 있다. 현재 AWS에서는 AI/ML 파이프라인을 구축하는 데 전념하고 있다.
저자
안티 바르트
AWS 뒤셀도르프 지사에서 AI/ML 분야 선임 개발자 애드버킷으로 재직 중이다. 동시에 Women in Big Data의 공동 창립자이며, 이전에는 데이터 센터 인프라, 빅데이터와 인공지능 애플리케이션에 중점을 둔 시스코(Cisco) 및 MapR의 엔지니어로 일한 경력이 있다. 세계 각국에서 열리는 AI/ML 콘퍼런스와 밋업에 참석하여 지식을 나누는 연설을 정기적으로 하고 있다. 오라일리가 주최하는 AI 관련 시리즈 프로젝트인 ‘AI Superstream events’에서 의장을 맡고 있으며 콘텐츠를 큐레이팅하고 있다.
역자
서진호
마이크로소프트 시니어 테크 에반젤리스트로 활동하다가 스탠퍼드 대학교에서 Advanced Project Management Certificate 과정을 수료했다. 또한 코세라 커뮤니티에서 클라우드 컴퓨팅, 빅데이터, 인공지능 콘텐츠 관련 온라인 강의 및 기술 데모 피드백을 전달하는 어드바이저로 활동했다. 현재는 서울과학종합대학원에서 AI 전략경영 석사와 프랭클린 대학교에서 Executive MBA 과정을 복수 전공하고 있다. 저서로는 2006년에 출간한 『마이크로소프트 IT 전략과 미래』(한빛미디어, 2006)가 있다.
역자
최미영
AWS 실리콘밸리 지사에서 AI/ML 분야 시니어 프로그래머 라이터로 재직 중이다. 아마존 세이지메이커의 모델 훈련에 관한 기술 문서 원문을 퍼블리싱하며, 특히 딥러닝 분야 컴퓨터 비전 모델과 자연어 처리 모델과 같은 대규모 모델 훈련 작업에 필요한 디버깅, 리소스 프로파일링, 데이터 및 모델 분산 훈련, 그리고 컴파일링 기술 문서를 담당하고 있다. 2019년 텍사스 주립대 댈러스 캠퍼스에서 물리학 박사학위를 취득하였다.
역자
이용혁(감수)
메가존클라우드에서 ML 플랫폼 엔지니어로 IT 경력을 시작하였으며, 현재는 클래스101에서 Personalized eXperience 팀을 이끄는 시니어 머신러닝 엔지니어이다. 개인화에 있어서 중요한 두 가지 요소인 머신러닝 엔지니어링과 모델링 사이에서 균형을 찾기 위해 클라우드 활용을 극대화하고 있다. 최근에는 머신러닝 엔지니어와 데이터 과학자가 본연의 업무에 집중할 수 있도록 클라우드 기반의 MLOps를 효율적으로 구축하는 데 많은 열정을 쏟아붓고 있다.
목차
CHAPTER 1 AWS 기반 데이터 과학 소개
1.1 클라우드 컴퓨팅의 장점
1.2 데이터 과학 파이프라인 및 워크플로우
1.3 MLOps 모범 사례
1.4 아마존 세이지메이커를 사용한 아마존 AI와 AutoML
1.5 AWS에서 데이터 수집, 탐색 및 준비
1.6 아마존 세이지메이커를 사용한 모델 훈련 및 튜닝
1.7 아마존 세이지메이커와 AWS 람다 함수를 사용한 모델 배포
1.8 AWS 스트리밍 데이터 분석 및 머신러닝
1.9 AWS 인프라 및 맞춤형 하드웨어
1.10 태그, 예산, 알림으로 비용 절감하기
1.11 마치며
CHAPTER 2 데이터 과학의 모범 사례
2.1 모든 산업에 걸친 혁신
2.2 개인별 상품 추천 시스템
2.3 아마존 레코그니션으로 부적절한 동영상 감지
2.4 수요 예측
2.5 아마존 프로드 디텍터를 사용한 가짜 계정 식별
2.6 아마존 메이시를 사용한 정보 유출 탐지 활성화
2.7 대화형 디바이스와 음성 어시스턴트
2.8 텍스트 분석 및 자연어 처리
2.9 인지 검색과 자연어 이해
2.10 지능형 고객 지원 센터
2.11 산업용 AI 서비스와 예측 정비
2.12 AWS IoT와 아마존 세이지메이커를 사용한 홈 자동화
2.13 의료 문서에서 의료 정보 추출
2.14 자체 최적화 및 지능형 클라우드 인프라
2.15 인지 및 예측의 비즈니스 인텔리전스
2.16 차세대 AI/ML 개발자를 위한 교육
2.17 양자 컴퓨팅을 통한 운영체제 프로그램
2.18 비용 절감 및 성능 향상
2.19 마치며
CHAPTER 3 AutoML
3.1 세이지메이커 오토파일럿을 사용한 AutoML
3.2 세이지메이커 오토파일럿을 사용한 트래킹 실험
3.3 세이지메이커 오토파일럿을 사용한 자체 텍스트 분류기 훈련 및 배포
3.4 아마존 컴프리헨드를 사용한 AutoML
3.5 마치며
CHAPTER 4 클라우드로 데이터 수집하기
4.1 데이터 레이크
4.2 아마존 아테나를 사용해 아마존 S3 데이터 레이크 쿼리하기
4.3 AWS 글루 크롤러를 통해 지속적으로 새 데이터 수집하기
4.4 아마존 레드시프트 스펙트럼으로 레이크 하우스 구축하기
4.5 아마존 아테나와 아마존 레드시프트 중에서 선택하기
4.6 비용 절감 및 성능 향상
4.7 마치며
CHAPTER 5 데이터셋 탐색하기
5.1 데이터 탐색을 위한 AWS 도구
5.2 세이지메이커 스튜디오를 사용한 데이터 레이크 시각화
5.3 데이터 웨어하우스 쿼리하기
5.4 아마존 퀵사이트를 사용한 대시보드 생성
5.5 아마존 세이지메이커 및 아파치 스파크를 사용한 데이터 품질 문제 감지
5.6 데이터셋에서 편향 감지하기
5.7 세이지메이커 클래리파이로 다양한 유형의 드리프트 감지
5.8 AWS 글루 데이터브루를 사용한 데이터 분석
5.9 비용 절감 및 성능 향상
5.10 마치며
CHAPTER 6 모델 훈련을 위한 데이터셋 준비
6.1 피처 선택 및 엔지니어링 실행
6.2 세이지메이커 프로세싱을 통한 피처 엔지니어링 확장
6.3 세이지메이커 피처 스토어를 통한 피처 공유
6.4 세이지메이커 데이터 랭글러를 사용한 데이터 수집 및 변환
6.5 아마존 세이지메이커를 사용한 아티팩트 및 익스페리먼트 계보 트래킹
6.6 AWS 글루 데이터브루를 사용한 데이터 수집 및 변환
6.7 마치며
CHAPTER 7 나의 첫 모델 훈련시키기
7.1 세이지메이커 인프라 이해하기
7.2 세이지메이커 점프스타트를 사용해 사전 훈련된 BERT 모델 배포하기
7.3 세이지메이커 모델 개발
7.4 자연어 처리 역사
7.5 BERT 트랜스포머 아키텍처
7.6 처음부터 BERT 훈련시키기
7.7 사전 훈련된 BERT 모델 미세 조정하기
7.8 훈련 스크립트 생성
7.9 세이지메이커 노트북에서 훈련 스크립트 시작하기
7.10 모델 평가하기
7.11 세이지메이커 디버거를 사용한 모델 훈련 디버깅 및 프로파일링
7.12 모델 예측 해석 및 설명
7.13 모델 편향 감지 및 예측 설명
7.14 BERT를 위한 추가 훈련 선택
7.15 비용 절감 및 성능 향상
7.16 마치며
CHAPTER 8 대규모 모델 훈련과 최적화 전략
8.1 최적의 모델 하이퍼파라미터 자동으로 찾기
8.2 세이지메이커 하이퍼파라미터 튜닝에 웜스타트 추가 사용
8.3 세이지메이커 분산 훈련으로 확장하기
8.4 비용 절감 및 성능 향상
8.5 마치며
CHAPTER 9 프로덕션에 모델 배포하기
9.1 실시간 예측 또는 일괄 예측 선택하기
9.2 세이지메이커 엔드포인트를 사용한 실시간 예측
9.3 아마존 클라우드워치를 사용한 세이지메이커 엔드포인트 오토스케일링
9.4 새 모델 또는 업데이트된 모델로 배포하는 전략
9.5 새 모델 테스트 및 비교
9.6 모델 성능 모니터링 및 드리프트 감지
9.7 배포된 세이지메이커 엔드포인트의 데이터 품질 모니터링
9.8 배포된 세이지메이커 엔드포인트의 모델 품질 모니터링하기
9.9 배포된 세이지메이커 엔드포인트의 편향 드리프트 모니터링
9.10 배포된 세이지메이커 엔드포인트의 피처 속성 드리프트 모니터링
9.11 세이지메이커 일괄 변환을 사용한 일괄 예측
9.12 AWS 람다 함수 및 아마존 API 게이트웨이
9.13 엣지에서의 모델 관리 및 최적화
9.14 토치서브를 사용한 파이토치 모델 배포
9.15 AWS DJL을 사용한 텐서플로우-BERT 추론
9.16 비용 절감 및 성능 향상
9.17 마치며
CHAPTER 10 파이프라인과 MLOps
10.1 머신러닝 운영
10.2 소프트웨어 파이프라인
10.3 머신러닝 파이프라인
10.4 세이지메이커 파이프라인을 사용한 파이프라인 오케스트레이션
10.5 세이지메이커 파이프라인으로 자동화하기
10.6 더 많은 파이프라인 종류
10.7 휴먼인더루프 워크플로우
10.8 비용 절감 및 성능 향상
10.9 마치며
CHAPTER 11 스트리밍 데이터 분석과 머신러닝
11.1 온라인 학습과 오프라인 학습의 비교
11.2 스트리밍 애플리케이션
11.3 스트리밍 데이터용 윈도우 쿼리
11.4 AWS에서 스트리밍 분석 및 머신러닝 구현하기
11.5 아마존 키네시스, AWS 람다, 아마존 세이지메이커를 사용한 실시간 상품 리뷰 분류
11.6 아마존 키네시스 데이터 파이어호스를 사용한 스트리밍 데이터 수집 구현
11.7 스트리밍 분석으로 실시간 상품 리뷰 요약하기
11.8 아마존 키네시스 데이터 애널리틱스 설정
11.9 아마존 키네시스 데이터 애널리틱스 애플리케이션
11.10 아파치 카프카, AWS 람다, 아마존 세이지메이커를 사용한 상품 리뷰 분류
11.11 비용 절감 및 성능 향상
11.12 마치며
CHAPTER 12 AWS 보안
12.1 AWS와 사용자 간의 공동 책임 모델
12.2 AWS IAM
12.3 컴퓨팅 및 네트워크 환경 격리
12.4 아마존 S3 데이터 액세스 보호
12.5 저장 시 암호화
12.6 전송 중 암호화
12.7 세이지메이커 노트북 인스턴스 보호
12.8 세이지메이커 스튜디오 보안
12.9 세이지메이커 작업과 모델 보안
12.10 AWS 레이크 포메이션 보호
12.11 AWS 시크릿 매니저를 통한 데이터베이스 자격 증명 보안
12.12 거버넌스
12.13 감사 가능성
12.14 비용 절감 및 성능 향상
12.15 마치며
출판사리뷰
AWS와 데이터 과학의 완벽한 융합을 통해,
비즈니스 성과를 극대화하는 프로젝트를 구축해보세요!
AWS의 다양한 서비스를 활용하여 안정적이고 확장성 있는 데이터 과학 인프라를 구축하는 기업이 많아지고 있습니다. 이 중에는 넷플릭스도 포함되며, EC2, S3, EMR, 레드시프트, 람다 등을 적극적으로 활용하여 비즈니스 성과를 극대화했습니다. 이러한 성과는 다른 기업에게도 큰 영향을 미치게 되었고, 그렇게 AWS 서비스는 데이터 과학 프로젝트에서 필수적인 요소 중 하나로 자리 잡게 되었습니다.
하지만 AWS를 활용하여 데이터 과학을 수행하는 방법에 대한 정보를 한곳에 모아둔 자료는 찾아보기 어렵습니다. 이 책은 이러한 아쉬움을 해결하기 위해, AWS를 활용하여 데이터 과학을 수행하고 비즈니스 성과를 높이기 위한 전체 과정을 안내합니다. 또한, AWS 비용 최적화에 대한 팁과 함께 일반적으로 겪을 수 있는 문제와 그 해결책, 그리고 보안에 대한 정보를 제공합니다. 이 책을 읽고 나면 여러분은 성공적인 데이터 과학 프로젝트를 위한 전문적인 기술과 전략을 숙지하여, 현업에서 높은 수준의 성과를 이룰 수 있게 될 것입니다.
"AWS기반 데이터 과학"은 요즘 많은 회사에서 활용하고 있는 AWS를 기반으로 데이터사이언스 프로젝트를 수행하는 방법에 대해서 설명하고 있다. 이전 회사에서는 온프레미스 환경에서 작업을 했으나, 사실 최근 많은 회사들에서는 AWS와 같은 클라우드 환경에서 작업하는 경우가 훨씬 많다. 그래서 한 번 관련해서 공부를 해야하지 않나 싶던 차에 이 책을 보게 되어 전체적인 데이터 사이언스 플로우에 대해 이해할 수 있어서 좋았다. AWS와 같은 클라우드 서비스를 사용하면 초기 구축에 대한 비용도 훨씬 적게 들고, 실제 모델을 개발하고 배포하는 경우에 대한 간극이 적어 운영하기에도 편하다는 장점이 있다고한다. 듣기만 했는데, 실제 구축하는 내용을 자세히 보니 모델을 학습하고 최적의 모델을 찾는 경우 훨씬 편하고 똑똑하게 운영할 수 있어 좋다는 생각이 들었다.
이 책은 앞 표지에 나온 것 처럼 엔드투엔드를 설명하고 있어 따라하며 실제 어떻게 운영할 수 있는지 감을 잡을 수 있어 좋았다. 특히 좋았던 건, 개념이나 기능에 대한 설명을 하는 것이 아니라 실제 활용에 대한 부분이 많았다는 점이다. 요즘 관심있게 보던 Automl이나 자연어처리사례를 추가해서 전체 플로우에 대한 내용을 따라갈 수 있었다. 또한 클라우드 환경에서 제일 이용자가 걱정하는 것은 아무래도 보안에 관한 이슈일 수 밖에 없는데, 이런 부분에 대해서도 마지막 장에서 설명하고 있어 이런 부분에 대한 이해도도 높일 수 있다.
완전 초보자를 위한 책은 아닐 뿐더러, 책 두께에서 오는 압박감도 있긴 하니 약간의 지식이 있는 사람들이 읽는 것이 좋을 것 같다.
요즘 ChatGPT는 어딜가나 화제입니다. 몇 일 전에는 네이버가 CLOVA X를 공개해서 주목받았고, ChatGPT와 비교하는 내용의 글은 SNS 등에서 쉽게 찾아 볼 수 있습니다. 꽤 오랜기간 잠잠했던 인공지능이 최근 놀라운 결과물을 쏟아낼 수 있도록 받쳐준 것은 클라우드입니다. ChatGPT와 같은 서비스를 만들기 위해서는 대규모 데이터 셋과 연산 능력이 필요한데 이를 위해 클라우드가 필수적입니다.
데이터 과학과 클라우드는 밀접한 관계를 맺고 있어 데이터 과학 프로젝트를 성공적으로 수행하려면 클라우드에 대한 이해가 필요합니다. 이런 데이터 과학과 클라우드의 관계로 AWS 클라우드를 활용하여 데이터 과학 프로젝트를 구축하는 방법을 다루고 있는 이 책이 나오게된 것 같습니다.
이 책의 저자 두 분은 AWS의 AI/ML 분야 개발자 애드버킷으로 근무하는 분들이니 AWS를 활용한 데이터 과학 프로젝트를 수행하는 방법에 대해서 잘 설명할 수 있는 분들일 것 같습니다. 역자 두 분 중 한 분은 저자들과 마찬가지로 AWS에서 AI/ML 분야에서 근무하는 분이고, 다른 한 분은 MS 테크 에반젤리스트로 업계에 잘 알려진 분이라 책을 펼쳐보기 전부터내용이 좋을 것 같은 기대가 있었습니다.
이 책은 데이터 과학 프로젝트에 활용할 수 있는 AWS의 인프라, 데이터 도구, AI/ML 스택과 서비스 그리고 보안에 이르는 많은 것을 다루고 있습니다. 데이터 과학 파이프라인과 워크플로우를 중심으로 각 단계에서 활용할 수 있는 AWS의 서비스를 설명하고, 데이터 과학 프로젝트 사용 사례에 AWS의 AI/ML 스택을 적용하여 활용법을 설명합니다. 특히 아직 번역자료가 부족한 세이지메이커(SageMaker)를 활용하여 데이터 과학 프로젝트를 수행하는 방법을 잘 보여줍니다.
데이터 과학과 클라우드 두 가지를 동시에 다루고 있어서 책 하나로 두 분야를 공부할 수 있다는 장점도 있지만 두 분야에 대한 기초적인 준비가 없으면 책 한 권을 모두 소화하지 못할 수도 있습니다. 데이터 과학과 클라우드에 대한 기초적인 내용을 한 번 살펴본 후에 이 책으로 AWS와 데이터 과학, 두 마리 토끼를 사냥해 보면 얻는 것이 많을 것 같습니다.
책을 직접 보지 못하셨겠지만 아무래도 아주 두꺼운 기술 관련 서적이다 보니 위압감이 장난이 아니었다. 과연 내가 이 책을 다 읽어볼 수나 있을까 하는 생각에 압도되는 느낌이랄까?
나름 책을 많이 읽어보고 읽어오고 있는 1인이라 나름 두꺼운 책도 거부감없이 잘 읽어왔는데 아물래도 기술 서적이다 보니 더 그런 포스를 느꼈던 것 같다. (다들 알지 않은가? 표지 전면에 동물 혹은 곤충 그림이 박혀 있고 두꺼운 책들이 뿜어내는 어마무시한 포스를^^; )
목차를 보아도 그 압박감을 다시 한 번 느낄 수 있었지만 단락별 제목과 소제목을 보면서 뭔가 친숙한 단어에 안정감을 되찾아가며 책을 훑어내려가기 시작했다.
그리고 다행스러운 부분은 아무래도 업무 간 부딪혀보고 겪어보며 친숙해진 단어와 내용들이 나를 맞이해주면서 속도를 높여갈 수 있었다.
이 책을 읽는데 있어 한 가지 팁을 주자면 처음부터 끝까지 읽지도, 100% 이해하면서 읽으려고 하지도 않았으면 한다는 것이다. 오히려 목차를 펴 놓고 원하는 내용 혹은 활용해보고자 하는 부분만 펼쳐서 천천히 읽어보는 것을 추천한다.
내가 필요에 의해 찾아서 읽는 부분은 이미 사전 이해가 어느정도 있는 상황이고, 막힌 부분을 찾아가는 여정을 이 책과 함께 한다면 더 재미있고 유의미하게 이 책을 읽고 활용할 수 있으리라 생각된다.
나는 한빛미디어 '나는 리뷰어다' 활동을 일환으로 책을 처음부터 끝까지 쑤욱 흝어보고 서평을 작성 중이긴 하지만 회사 자리에 이 책을 올려놓고 종종 꺼내보며 공부를 하지 않을까 생각이 든다. 이게 진짜 제대로 된 기술 서적의 활용법이 아닐까 싶다^^
자주 접하고 활용했던 E2C 서버 및 IAM, ATENA 등 서비스 내용이 나왔을 때는 친숙함에 속도가 쫙쫙 나가다가도 머신러닝과 관련된 내용이 나오면 더뎌지기도 했지만 도움이 되는 내용이 너무나도 그득그득 들어차 있어 향후 나의 개발자로써의 성장 일기에 많은 영향을 줄 수 있는 책이 아닐까 싶다.
이 책은 AWS 서비스를 사용하여 데이터 과학 프로젝트를 수행하는 방법을 알려주는 도서입니다.
Amazon SageMaker와 같은 머신 러닝에서부터 Lex, DeepLens, Macie와 같은 AI 서비스를 포함하였습니다.
AWS 서비스를 무려 80여 가지를 사용하였는데 용어 리스트를 별도로 제공하여 가뜩이나 축약어가 많은
AWS 제품명을 잊지 않게 해줍니다. 또한 #AutoML, #MLOps, #자연어처리 등, 자주 들었던 기술들이 어떤 비즈니스 요구사항에 대한 해결 방안이 될 수 있는지를 잘 알려줍니다.
이 도서에서 언급한 - AWS 클라우드를 활용하여 데이터 과학 프로젝트를 수행할 때 자주 사용되는 제품과 그 효과는 다음과 같습니다.
Amazon S3 (Simple Storage Service):
대용량의 데이터를 저장하고 관리하는 데 사용됩니다. 데이터 레이크를 구축하거나 원시 데이터를 저장하는데 유용합니다.
Amazon Redshift:
데이터 웨어하우스로 사용되며 대용량 데이터의 분석과 쿼리에 최적화되어 있습니다.
Amazon RDS (Relational Database Service):
관계형 데이터베이스를 호스팅하고 관리하는 데 사용됩니다. 프로젝트에서 구조화된 데이터를 저장하거나 필요한 경우 SQL 질의를 수행할 수 있습니다.
Amazon EMR (Elastic MapReduce):
대규모 데이터 처리 작업을 위해 Hadoop 및 기타 분산 컴퓨팅 프레임워크를 활용합니다.
Amazon SageMaker:
머신러닝 모델 훈련, 평가, 배포를 간소화하는 머신러닝 플랫폼입니다. AutoML, 모델 개발 및 훈련, 엔드 포인트 배포 등 다양한 단계에서 사용됩니다.
Amazon Kinesis:
스트리밍 데이터를 처리하고 분석하는 데 사용됩니다. 실시간 데이터 스트리밍 분석에 유용합니다.
Amazon QuickSight:
비즈니스 인텔리전스 및 데이터 시각화 툴로 사용되며, 데이터를 직관적인 대시보드로 시각화하여 분석할 수 있습니다.
Amazon Comprehend:
자연어 처리(NLP)를 통해 텍스트 데이터를 분석하고 감정 분석, 키워드 추출, 문서 분류 등을 수행할 수 있습니다.
Amazon Rekognition:
이미지 및 비디오 분석을 통해 객체, 얼굴, 텍스트 등을 감지하고 분류하는 데 사용됩니다.
이 외에도 AWS는 다양한 서비스를 제공하며, 데이터 저장, 처리, 분석, 머신러닝, 보안, 인프라 관리 등 다양한 단계에서 활용할 수 있는 기능을 제공합니다. 데이터 과학 프로젝트에서 이러한 AWS 서비스를 조합하여 필요한 작업을 효율적으로 수행하고 프로젝트의 성공을 이끌어내는데 활용할 수 있습니다.
자칫 어려운 개념의 내용들이지만 다이어그램과 삽화의 도움으로 이해를 쉽게 가져갈 수 있습니다.
이 책은 AWS 기반 데이터 과학에 관한 다양한 주제를 다루고 있습니다. 각 장의 주요 내용과 특징은 다음과 같습니다.
CHAPTER 1 AWS 기반 데이터 과학 소개: 이 장은 클라우드 컴퓨팅의 이점, 데이터 과학 파이프라인 및 워크플로, MLOps 모범 사례, 아마존 세이지메이커를 사용한 데이터 과학 및 AutoML, AWS에서 데이터 수집 및 처리, 모델 훈련 및 배포, 스트리밍 데이터 분석 등을 소개합니다.
CHAPTER 2 데이터 과학의 모범 사례: 다양한 산업에서의 데이터 과학 활용 사례와 예시를 다룹니다. 상품 추천 시스템, 이미지 감지, 수요 예측, 가짜 계정 식별, 정보 유출 탐지, 음성 어시스턴트, 텍스트 분석, 고객 지원 센터 개선, 예측 정비, 홈 자동화 등 다양한 영역에서의 데이터 과학 적용 사례를 다룹니다.
CHAPTER 3 AutoML: 세이지메이커의 AutoML 기능을 사용하여 자동화된 머신러닝 모델 훈련을 소개합니다. 오토파일럿을 사용한 AutoML, 데이터 셋 트래킹, 자체 텍스트 분류기 훈련 및 배포, 아마존 컴프리헨드를 활용한 AutoML 등이 포함됩니다.
CHAPTER 4 클라우드로 데이터 수집하기: 클라우드 환경에서 데이터 레이크를 구축하고 데이터를 수집하는 방법을 다룹니다. 데이터 레이크, 아마존 아테나와 아마존 S3 데이터 쿼리, 데이터 수집을 위한 AWS 글루 크롤러, 레이크 하우스 구축 등을 다룹니다.
CHAPTER 5 데이터 셋 탐색하기: 데이터 탐색과 시각화를 위한 AWS 도구와 기법에 대해 설명합니다. 세이지메이커 스튜디오를 활용한 데이터 레이크 시각화, 데이터 웨어하우스 쿼리, 대시보드 생성, 데이터 품질 문제 감지, 데이터 편향 감지 등을 다룹니다.
CHAPTER 6 모델 훈련을 위한 데이터 셋 준비: 모델 훈련에 필요한 데이터 셋을 준비하는 과정과 세이지메이커 기능을 활용한 피처 엔지니어링, 피처 공유, 데이터 변환 등을 다룹니다.
CHAPTER 7 나의 첫 모델 훈련시키기: 세이지메이커를 사용하여 모델을 훈련하는 방법을 설명합니다. BERT 모델을 활용한 자연어 처리 모델 훈련 예시와 모델 평가, 디버깅, 예측 해석 등을 다룹니다.
CHAPTER 8 대규모 모델 훈련과 최적화 전략: 대규모 모델 훈련과 하이퍼 파라미터 튜닝, 세이지메이커 분산 훈련 등을 다루며, 최적의 모델 성능을 위한 전략을 제시합니다.
CHAPTER 9 프로덕션에 모델 배포하기: 훈련된 모델을 실제 환경에 배포하는 방법과 모델 보안, 모니터링, 업데이트 전략 등을 다룹니다.
CHAPTER 10 파이프라인과 MLOps: 머신러닝 파이프라인과 MLOps(머신러닝 운영)의 개념을 소개하고 세이지메이커 파이프라인을 사용한 파이프라인 구축과 자동화 방법을 설명합니다.
CHAPTER 11 스트리밍 데이터 분석과 머신러닝: 스트리밍 데이터를 활용한 실시간 데이터 분석과 머신러닝 구현 방법을 소개합니다.
CHAPTER 12 AWS 보안: AWS 환경에서의 데이터 및 모델 보안, IAM(Identity and Access Management), 데이터 액세스 보호, 암호화, 보안 관리 등을 다룹니다.
이 책을 통해 AWS 기반 데이터 과학에 관한 종합적인 지식을 습득할 수 있으며, 클라우드 환경에서 데이터 처리, 모델 훈련, 배포, 모델 보안 및 모니터링 등 다양한 주제를 다룰 수 있습니다. 데이터 수집 및 처리, 머신러닝, 배포 등의 모든 과정을 상세히 다루는 것은 물론, AWS 서비스와 도구에 대한 명확한 설명과 실용적인 모범 사례까지 제공하기 때문에 AWS 기반의 데이터 분석 및 과학 프로젝트를 수행하는 개발자들에게 이 도서를 추천합니다.
목차를 보는 것도 상당 시간이 걸릴 정도로 이 책은 데이터를 다루는 거의 모든 영역과 대부분의 AWS 서비스에 대한 내용을 다루고 있습니다. 과연 이 내용들을 다 이해 할 수 있을까? 라는 의문이 들었는데...
책을 빠르게 보면서 의문은 자연스레 해결이 되네요. 어떤 부분은 자세히 설명이 되어 있지만, 또 다른 부분들은 간단하게 핵심만 언급하고 지나가는 부분도 보입니다. 이런 부분들은 아마 경험이 있거나 이전에 공부한 사람들이 아니면 도대체 뭔소리인가 넘어갈듯 합니다. 책의 분량이 상당함에도 불구하고 방대한 영역을 모두 자세히 설명하는 것은 역시 무리수인거죠.
또한 이 책의 중반 부터 절반 이상은 머신러닝/딥러닝에 대한 내용을 다루고 있습니다. 요즘 유행하는 chatGPT에 대한 내용은 아니지만, 예전에 유명했던 BERT 모델에 대해 주로 설명하고 있습니다. 사실 BERT 같은 언어 모델은 개념이 많이 어렵기 때문에 이해 하는게 쉽지 않습니다. 당연하거지만 통계나 수학적인 지식이 필요하지만 이 책은 그런 부분은 대부분 생략되어 있습니다. 한빛미디어 사이트에 가서 보니 역시나 이 책은 중고급 대상으로 나와 있네요. 제가 보기엔 중급자들도 어려울거 같은 느낌.
책의 마지막에는 클라우드에서 역시 중요한 보안과 네트워크에 대해서도 한 챕터를 할당해서 설명이 있습니다.
이 책은 정말 모든 챕터가 대부분 주옥 같은 내용들이라 자세한 설명이 없는 부분에 대해서는 다른 책이나 AWS 매뉴얼을 참고 해야 합니다. 특히 제가 개인적으로 관심 있었던 추천 시스템, MLOps, mlflow, AutoML 등도 짧게나마 설명이 있어서 좋았습니다.
결론, AWS 를 사용하거나 데이터를 다룬는 직군, 머신러닝/딥러닝을 한다면 꼭 이책을 한번 보시기를 권합니다.
다양한 내용을 보면서 자신이 어떤 부분에 취약한지 금방 알 수 있게 해주는 그런 책입니다.
이 책은 언젠가 꼭 읽어 보고 싶었던 책이었다. 강의를 하며 학생 중 누가 이 책을 보고 있어서 책 표지만 봤었는데, 자세하게 책에 대해 그 학생에게 물어보지를 못해서 책 내용은 모른채 꼭 읽어봐야겠다라는 생각만 있었던 책이었다. 이번 리뷰를 통해 드디어 내 손에 들어온 책이 그래서 어느 책보다도 기대감이 컸다.
사실 AWS 같은 CSP 벤더에서는 생성형 AI같은 최신 트렌드나 새로운 비즈니스를 위한 새로운 도구보다 데이터 과학이라는 분야가 그리 썩 비중있게 다룰 것이라고 생각하지 않았다. 아무래도 벤더입장에서도 우선순위가 있을 것이고, 회사의 수익을 따져보면 어림잡을 수 있을 것이다. 하지만 이 책은 그런 선입견을 어느 정도 해소한 부분이 많게 해 준 책이다.
얼마전 모 대학에서 Datalake를 한 한기 강의한 적이 있었는데, 주로 AWS 기반 리소스를 이용했었다. Batch processing, Realtime processing을 AWS 기반의 다양한 서비스를 이용해서 데이터 처리를 했었다. 전통적인 Kafka나 Hadoop, 그리고 Spark를 Java와 Python으로 핸들링했었는데, 그러면서 AWS의 다양한 서비스에 놀랐던 기억이 있다. 이 책은 더 나아가 MLOps와 보안 그리고 다양한 관점을 알게 해 준 책이다. 이 책을 통해 Data Analysist, Data Scientist 뿐만 아니라 Data Engineer로 직업을 고민하는 많은 분들과 현직에서 데이터분석 업무를 하는 분들이 더 깊은 데이터 과학의 길을 찾을 것이다.
ChatGPT의 인기와 더불어 AI의 기술 발전 속도가 어마어마하다. 이러한 AI의 기술 발전 속도에 발 맞추어 아마존 AWS에는 수많은 서비스가 있다. 기본적인 클라우드 컴퓨팅에서 부터, 스토리지 서비스, 보안 등 제공하고 있는 서비스의 명칭이 어디 카테고리에 속하는지 헷갈릴 정도이다. 출판사에서 소개하고 있는 소개 페이지 글은 다음과 같다..
AWS의 서비스 중 클라우드와 웹서비스에 대한 소개 서적은 많은데, 인공지능 + 데이터 과학 서비스를 중점적으로 다룬책은 드물고 이 책은 Amazon SageMaker를 포함하여 인공지능 + 데이터 과학 서비스 중심으로 다루고 있다.
책의 전반부에서는 머신러닝의 일반적인 워크플로우와 아마존 AI, ML에 대한 전반적인 설명을 하고 있다.
---
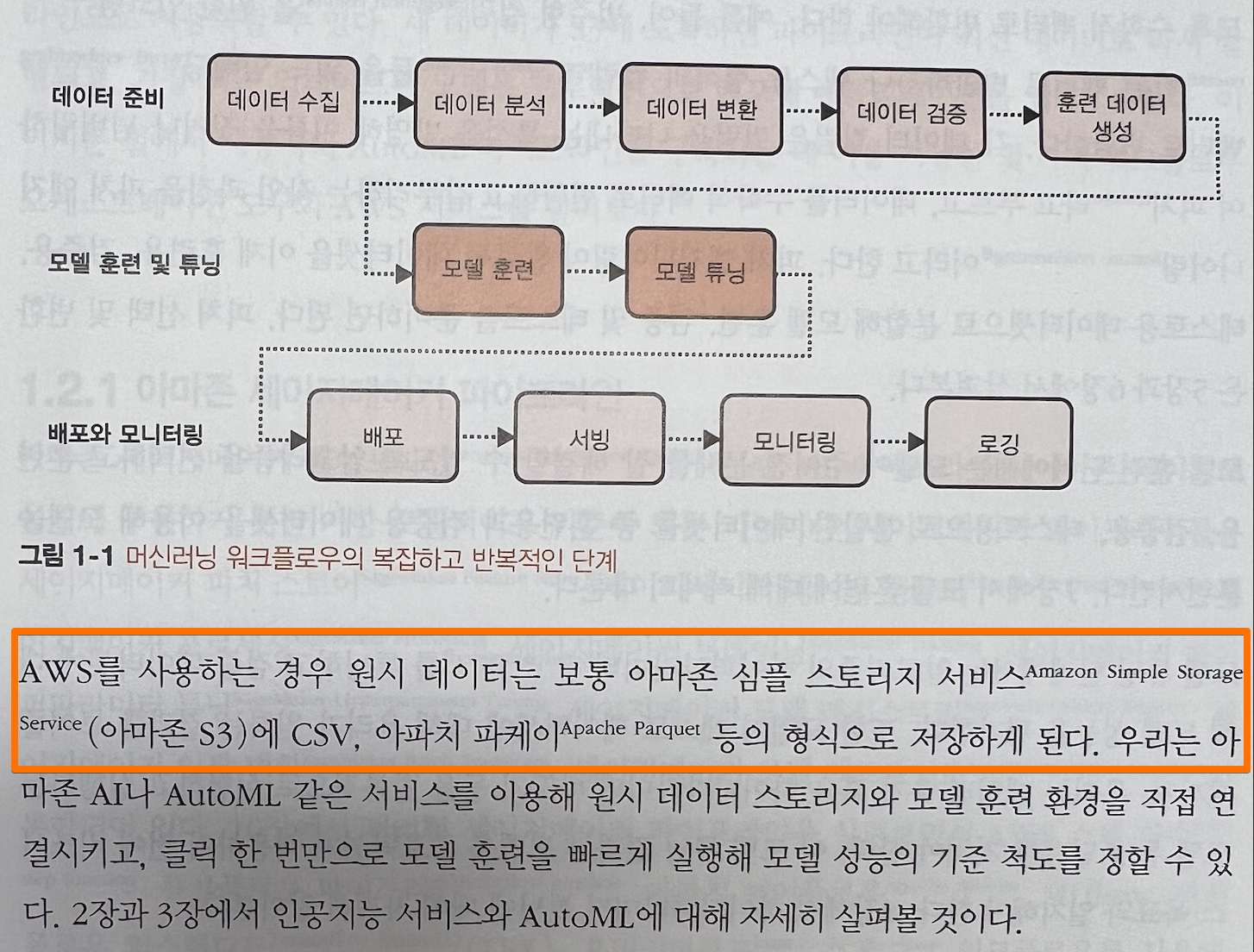
데이터 준비 -> 모델 훈련 및 튜닝 -> 배포와 모니터링
---
이러한 워크플로우를 따라가며, AWS의 서비스중 어떠한 것을 적재적소에 사용해야 하는지 그 서비스는 무엇인지 설명하는 방식을 취한다.
단순히 AWS 서비스를 나열하여 설명하는데 그치는 것이 아니라 실질적인 예제와 실질적인 도표를 통해 최대한 시각적으로 표현해 주어 이해도를 높여 주고 있다. 아마 두 공동저자가 현업 AWS 근무하는 직원이어서 서비스들에 대한 이해도도 깊고 그러한 서비스들을 어떻게 활용해야하는지 잘 알고 있으며, 그렇기에 더 친절하게 설명이 가능한 것이라 짐작해 본다.
또한 유독 책 하단에 '옮긴이'의 주석이 많은 것도 인상적이다. 배경지식이 부족하거나 이해가 힘든 부분에 있어 최대한 '옮긴이'의 주석을 통해 쉽게 이해할 수 있도록 역자 두분이 친절하게 설명해 주고 있다.
AWS를 활용하여 AI/ML 파이프라인을 구성하고 최적의 비용으로 서비스하는 프로덕션 레벨의 서비스를 만들고자 한다면 이 책 "AWS기반 데이터 과학'은 훌륭한 길잡이가 될 수 있을 것이다.
AWS에 수많은 서비스가 있습니다. 기본적으로 가장 많이 사용하는 EC2, S3, RDS등 웹서비스를 구성하기 위한 서비스 이외에 정말 많은 서비스가 제공됩니다. 이제 가지수를 하나하나 세워보는것은 의미가 없습니다. 서비스들이 계속 추가되고 그 속도가 매우 바쁩니다.
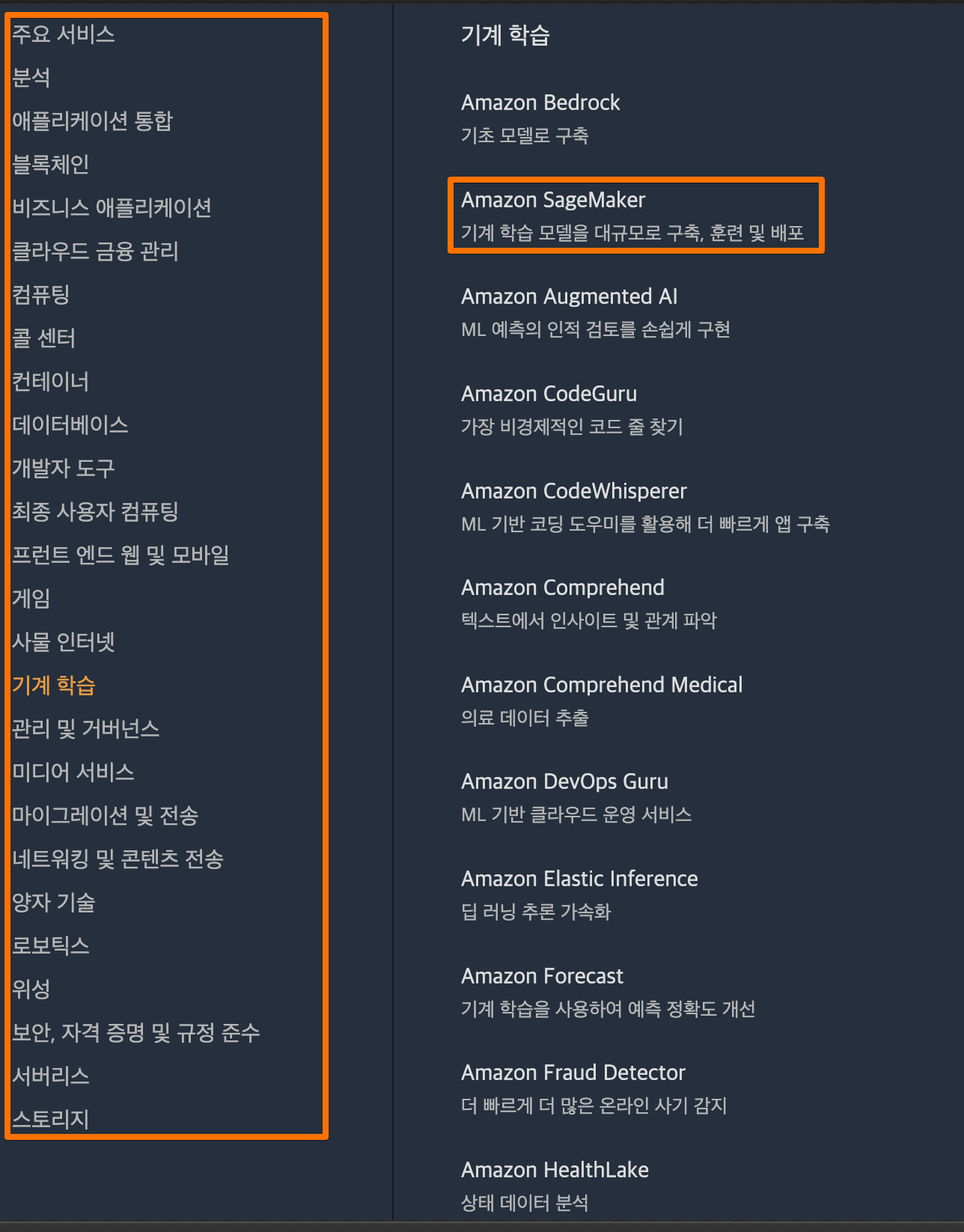
아래 왼쪽에는 대분류 카테고리 입니다. 이 항목이 "카테고리"입니다. 아래 "기계학습" 카테고리를 클릭했을때 오른쪽에 매우 다양한 AWS서비스 리스트를 확인할수 있습니다.
우리는 이렇게 다양한 모든 서비스를 다 사용할 수 없습니다. AWS에서 우리가 서비스하는 목적에 맞게 적절한 선택을 해야 합니다. 하지만 일반적으로 AWS를 다루는 책이 많이 있습니다. 일반적인 AWS의 필수기능 및 웹서비스를 하기 위한 항목, 가장 많이 사용하는 서비스에 대한 설명이 위주로 되어 있습니다. AWS를 사용하는 사용자 중에 "데이터 과학"에 대해서 사용하려면 어떠한 서비스를 이용해야 할지 막막한 부분인데, 그것에 대해서 좋은 자료를 찾는다면 해당 책이 그 답이 될 것 같습니다.
아래와 같은 주안점으로 책을 살펴보려고 합니다.
AWS 다양한 새로운 서비스에 대해서 잘 설명을 하고 있는지 궁금
책의 가격이 저렴하지 않지만, 그 가격의 충분한 가치를 가지고 있을까?
데이터과학에 대한 부분이 잘 설명되고 있는가?
AWS의 AI/ML분아 재직중이신 2분이 공동저자분에 내용구성에 기대감
처음 이 책을 보았을때, 좋았던 부분은 아래와 같습니다.
우리가 데이터를 다루지 않는 분야가 있을까요? 아마 모두 어느 정도의 기능단위 개발 후에 누적된 데이터를 기반으로 다른 사업, 서비스의 고급화, 개인화, 추천등으로 이어지는 것은 매우 당연한 흐름입니다.
그러한 면에서 꼭 데이터과학에 대한 전문적인 직업 포지션을 가지고 있지 않은 분들도 이 책은 도움이 되는 부분이라고 생각이 들었습니다.
지금 당장은 사용하지 않지만, 추후에 온프레미스(On-premise) 환경에서 서비스를 구축하기 어려운 환경이면 결국 클라우드 시스템을 이용할수 밖에 없습니다. 이 책은 단순히 AWS에서 이러한, 저러한, 여러가지 서비스를 제공하고 있다는 소개 뿐만이 아니라, 데이터 과학을 즉 데이터를 잘 다루는 이론적인 부분도 충분히 설명이 되어 있기 때문에, 이러한 이론 및 구현하고 싶은 항목을 기준으로 AWS에 제품에 대한 전반적인 동작 방식 및 사용법을 알아갈수 있게 해줍니다. 또한 여려가지 AWS서비스의 구성 조합에 대한 적절한 조합 및 방향성을 알려주는 부분이 좋았습니다.
"이 책의 목표는 AWS에서 데이터 과학 프로젝트의 비용을 절감하고 성능을 향상하는 팁을 제공하는 것이다" (by. p.19)
■ 책이 구성
· 소개글이 매우 잘 되어 있고, 꼼꼼히 살펴보면 책의 구성과 언급되는 기술에 대해서 파악하기 용의합니다.
· 1장 : 아마존 AI.ML에 대해서 개략적 설명
· 2장 : 추천시스템, 자연어 이해 등등 아마존 Al과 ML스택을 적용
· 3장 : 세이지메이커 오토파일럿의 AutoML 사용
· 4~9장 : 데이터의 수집 및 분석, 피처 선택 및 엔지니어링, 모델훈련 및 튜닝, 아마존세이지메이커, 아마존 아테나, 아마존 레드시프트, 아마존 EMR, 텐서플로우, 파이토치, 서비리스 아피치 스파크를 활용한 모델배포, BERT기반 자연어 처리 NLP의 전체 모델 개발 라이프 사이클
· 10장 : 세이지메이커 파이프라인, 큐브플로우 파이프라인, 아파치 에어플로우, MLflow, TFX와 함께 MLOps를 사용해 모든 것을 반복하는 파이프라인으로 통합
· 11장 : 아마존 키네시스와 아파치 카프카를 사용한 실시간 데이터 스트림
· 12장 : AWS IAM, 인증, 권한부여, 네트워크 격리, 미사용 데이터 암호화, 전송중 양자 내성 네트워크 암호화, 거버넌스, 감사 가능성
각 항목마다 AWS의 서비스 제품들이 목적에 맞게 구성되어 있습니다. 책에서는 AWS의 제품명을 영어로 사용하지 않고 한글로 사용합니다. 4~9장에서 다루는 내용에서 "데이터의 수집 및 분석, 피처 선택 및 엔지니어링, 모델훈련 및 튜닝"에 대한 내용은 꼭 AWS와 무관한 부분으로 구성된 내용도 좋았습니다.
■ 책이 구성
· 이론적인 부분을 설명을 하면서, 자연스럽게 AWS에서 사용하게 될 일반적인 구성을 설명해주는것이 좋았습니다.
보통 서비스하는 항목들이 많아서, 어떤 서비스를 어떤 기능에 사용하게 될지 선택하기 어려운데, 이렇게 가이드를 주는내용은 곳곳에 언급됩니다. "그래서 AWS의 서비스를 전반적으로 파악하는데, 도움을 많이 받게 됩니다."
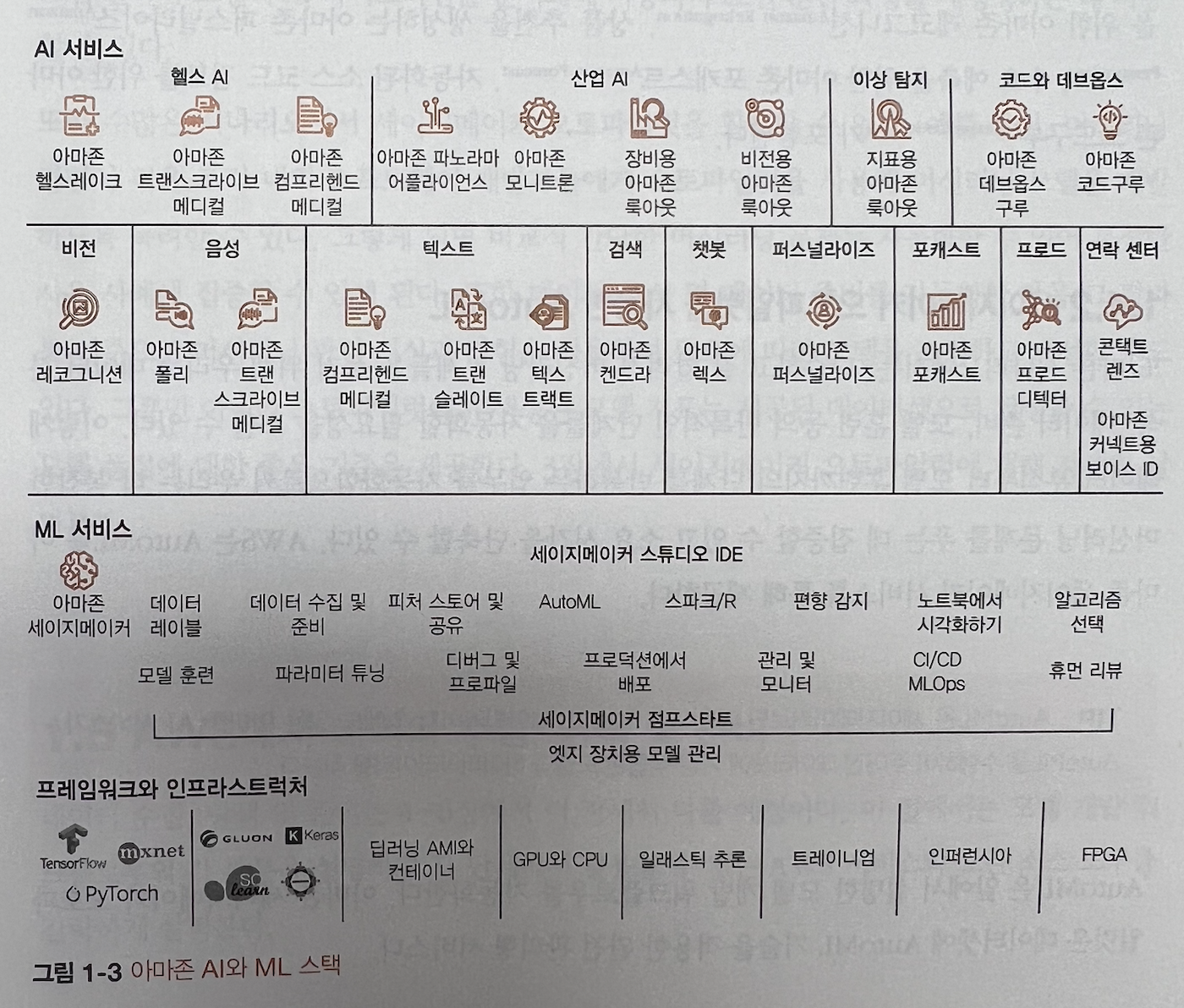
· 아주 좋은 AWS기술 스택 그림이다. 일반적으로 영어도 된 글자를 보다가, 어색할수 있습니다. 책에서는 가능한 대부분을 한글로 표기를 하였습니다.
혼돈을 막기 위해서 부록에서 영어서비스명과 한글로 번역한 사항이 정리되어 있습니다.
· 세이지메이커 오토파일럿은 투명한 AutoML의 표준이다.첵에서도 이것과 관련된 부분에 대해서 상세히 설명을 하고 있다.
· 데이터 분석을 위해서 서비스를 정했는데, 비용과 관련이 있는 부분은 항상 고민입니다. 그 이유는 각각의 인스턴스의 타입도 종류가 많습니다. 책에서는 이러한 부분도 설명되어 지고 있어서 실무에서 사용할때, 좋은 가이드를 세울수 있습니다.
■ 모범사례를 통해서 경험하는 간접체험
· 개인별 상품 추천 시스템 / 부적절한 동영상 감지 / 수요예측 / 가까 계정 식별 / 정보 유출 탐지 활성화 등등 2장에서 제시되는 사례목록은 아래와 같습니다.
CHAPTER 2 데이터 과학의 모범 사례
2.1 모든 산업에 걸친 혁신 2.2 개인별 상품 추천 시스템 2.3 아마존 레코그니션으로 부적절한 동영상 감지 2.4 수요 예측 2.5 아마존 프로드 디텍터를 사용한 가짜 계정 식별 2.6 아마존 메이시를 사용한 정보 유출 탐지 활성화 2.7 대화형 디바이스와 음성 어시스턴트 2.8 텍스트 분석 및 자연어 처리 2.9 인지 검색과 자연어 이해 2.10 지능형 고객 지원 센터 2.11 산업용 AI 서비스와 예측 정비 2.12 AWS IoT와 아마존 세이지메이커를 사용한 홈 자동화 2.13 의료 문서에서 의료 정보 추출 2.14 자체 최적화 및 지능형 클라우드 인프라 2.15 인지 및 예측의 비즈니스 인텔리전스 2.16 차세대 AI/ML 개발자를 위한 교육 2.17 양자 컴퓨팅을 통한 운영체제 프로그램 2.18 비용 절감 및 성능 향상 2.19 마치며
이러한 사항에 대해서 매우 흥미로운 사항들이 매우 많이 있습니다. 어느 도메인의 서비스에서도 모두 검토해서, 적용해볼만한 것들입니다.
이책은 AWS책이여서, 아래와 같이 AWS서비스를 활용한 구성도로 설명하는 부분이 매우 좋았습니다.
■ 데이터 수집하기
· 해당 분야는 정말 어느분들이나 관심있게 보실수 있는 분야입니다. 꼭 ML,AL을 다루지 않는다고 하여도 우리는 데이터를 collect하고 save하는 것은 서비스를 운영하는데, 필수요소입니다. 서버를 구매해서 환경구축을 하는것은 장점도 있지만, 단점도 분명히 존재합니다. 그래서 이러한 AWS의 서비스구성을 잘 알아두면 필요할 때, 파일럿 형태로 서비스를 구성해 볼수 있어서 장점이 더 많은것 같습니다.
· 데이터 레이크를 대규모의 다양한 데이터셋에 엑세스 할수 있도록 구성하는 것을 S3, 아테나, 글루 크롤러, 레드스피트 스펙트럼등을 통해서 코드베이스로 설명이 되어진다. 이론적인 부분만 설명하는 것이 아니라, 실제 구현샘플 코드를 기반으로 작성되어 있어서, 엔지니어 입장에서는 이해가 조금더 편하게 다가옵니다.
이런 비용절감 및 상세한 비교표는 이책에서만 있는 것이 아닐까 생각합니다.
■ 데이터 분석하기, 데이터셋 준비
· 본적적으로 세이지메이커, 레드시프트, 글루 데이터브루 를 활요하는 내용으로 구성됩니다.
· 일반적은 머신러닝, 딥러닝 책과는 조금 다른 느낌이 드는 책입니다. 이론적인 것보다 실제 서비스를 활용한 데이터 분석이라는 측면에서 조금더 가시적으고, 현업에서 사용하기에 무리가 없는 설명가이드 및 차트를 통한 가시화되는 부분이 책에 잘 녹아져 있습니다.
· 세이지메이커 프로세싱을 통한 피처 엔지니어링 부분에서 피처를 구성하고, 텐서플로우, 사이킷런, BERT를 사용하여 클러스터에 전체 데이터셋을 균형을 맞추고 분할/변환을 진행합니다.
· 세이지메이커 인프라를 활용하여서, 모델의 학습을 진행합니다.
■ 잘 만든것을 배포하기
· 프로덕션에 모델 배포하기위한 다양한 기법을 소개합니다. 모델을 업데이트 하고, 품질에 대한 검증을 AWS를 이용해서 구성하는것이 인상적이였습니다. 특히 AWS 람다 함수 및 아마존 API 게이트웨이의 부분은 일반적인 서비스에서도 참고할 만한 내용이며, 이러한 부분이 연결이 되어서 최종 파이프라인과 MLOps의 구성을 완성하게 됩니다.
· 마지막 장에 언급된 AWS 보안 부분은 일반적으로 알고 있는 IAM이외에 다른 고려사항도 언급되어 있어서, 관련된 부분을 AWS의 전반적으로 사용하는데 도움이 되는 내용으로 구성되어 있습니다.
12.1 AWS와 사용자 간의 공동 책임 모델 12.2 AWS IAM 12.3 컴퓨팅 및 네트워크 환경 격리 12.4 아마존 S3 데이터 액세스 보호 12.5 저장 시 암호화 12.6 전송 중 암호화 12.7 세이지메이커 노트북 인스턴스 보호 12.8 세이지메이커 스튜디오 보안 12.9 세이지메이커 작업과 모델 보안 12.10 AWS 레이크 포메이션 보호 12.11 AWS 시크릿 매니저를 통한 데이터베이스 자격 증명 보안 12.12 거버넌스 12.13 감사 가능성 12.14 비용 절감 및 성능 향상 12.15 마치며
책의 전반적인 수준이 높고, AWS를 사용하면서 일반적으로 알아야 되는 부분이 많아서 조금 놀랬습니다. 데이터 과학의 특화된 부분의 내용구성을 설명하면서, 자연스럽게 범용적으로 활용할수 있는 내용도 많았고, 비용절감적인 부분, 인스턴스의 비교표를 통해서 효율적으로 AWS를 사용할수 있는 노하우가 많이 설명되어지는 책이라고 생각합니다.
(컴퓨팅 : 모든 프로그램의 컴퓨팅 성공에 필요한 처리 성능, 메모리, 네트워킹, 스토리지 및 기타 리소스를 지칭하는 데 사용)
“Amazon Web Services(AWS)는 전 세계적으로 분포한 데이터 센터에서 200개가 넘는 완벽한 기능의 서비스를 제공하는, 세계적으로 가장 포괄적이며, 널리 채택되고 있는 클라우드입니다. 빠르게 성장하는 스타트업, 가장 큰 규모의 엔터프라이즈, 주요 정부 기관을 포함하여 수백만 명의 고객이 AWS를 사용하여 비용을 절감하고, 민첩성을 향상시키고 더 빠르게 혁신하고 있습니다.”
쉽게 말해 클라우드 컴퓨팅은 인터넷을 통해 ‘요구가 있을 때’ IT 리소스들을 종량제 형식으로 제공하는 서비스로 우리는 클라우드 컴퓨팅을 통해 자체 데이터 센터와 서버를 구매, 소유 및 유지하는 대신 컴퓨팅 파워, 스토리지, 데이터베이스, 기타 서비스와 같은 기술을 필요한 상황에 필요한 만큼 사용할 수 있다
클라우드 컴퓨팅이 없다면 나는 데이터 센터도 사야 하고 서버도 사야 하고 그걸 유지해야 하는 등
막대한 비용이 들겠지만 AWS 같은 클라우드 컴퓨팅 서비스로 합리적인 가격에 걱정 없이 필요한 컴퓨팅 자원들을 사용할 수 있다
그런 컴퓨팅 서비스를 지원하는 게 AWS다
하지만 AWS는 단순 클라우드 컴퓨팅은 아니다
AWS를 통해 데이터 과학 프로젝트도 진행할 수 있다
우리는 이 책을 통해 AWS 사용법을 익히고 데이터 과학 실습을 진행할 수 있다
목차는 이렇다
AWS에 관심 있는 사람들이 이 책을 읽어야 하는 이유는 뭘까?
크게 4가지가 있다
AWS 공식 문서에서 제공하는 80여 가지 서비스가 이 책에 담겨있다
AUTOML, MLOps, 및 자연어 처리 등의 기술로 비즈니스 문제 해결을 이해할 수 있다
이해하기 쉽게 직관적인 그림들과 정리된 표, 그림들이 제공된다
AWS 현업자의 보충 설명을 통해 이해를 돕는다
이 책을 읽어보면
초보를 위한 책은 아니다
한빛미디어 홈페이지에 들어가면 이 책 난이도를 중고급으로 소개하고 있다
쉬운 책은 당연히 아니다
하지만 AWS를 더욱 효율적으로 사용하고 싶다면
이 책을 읽어야 한다
괜히 이 책이 AWS 분야 아마존 베스트셀러가 아니다
AWS를 어떻게 다룰지부터 모르겠다면
한빛미디어에서 나온 AWS 입문 책을 먼저 읽어보길 추천한다
이 책은 기본적으로 AWS를 다룰 줄 알거나 AWS를 더 잘 활용하고 싶은 모든 사람들에게 추천한다
현시대는 오픈 AI의 ChatGPT가 인공지능 기술에 대한 대중의 이해도를 높이면서, 기업들은 물론 일반인들도 인공지능에 관심을 가지게 되었습니다. 그동안 인공지능이란 컴퓨터 과학자나 데이터 과학자의 특정한 전유물로만 여겨졌지만, 이제는 초등학생까지도 ChatGPT를 사용할 만큼 인공지능이 더욱더 친숙해졌습니다. 데이터 과학이란 비즈니스에 대한 의미 있는 인사이트를 추출하기 위한 데이터 연구로서, 수학, 통계, 인공 지능 및 컴퓨터 공학 분야의 원칙과 사례를 결합하여 대량의 데이터를 분석하는 종합적인 접근 방식입니다. 이 분석은 데이터 과학자가 무슨 일이 일어났는지, 왜 그런 일이 일어났는지, 무슨 일이 일어날지, 결과로 무엇을 할 수 있는지와 같은 질문을 하고 답하는 데 도움이 됩니다. 이 중 AWS는 클라우드의 표준을 이끌어가고 있는 제품으로 자체로 글로벌 규정을 철저하게 준수하는 보안기준을 가지고 있고 각각의 분야에 전문인력이 배치되어 있어 네트워크, 데이터베이스, 보안에 관해서 부담이 적으며 한국어 지원이 가능하고 사용자의 목적에 필요한 서비스만 골라서 사용이 가능하므로 기업 및 개인적으로 학습하기에도 매우 유용하게 사용되고 있는데 이 책에서는 이러한 AWS 클라우드에서 제공하는 세이지메이커를 활용하여 데이터 과학을 다룹니다.
제가 이 책을 선택한 이유는 AWS 기반의 AI와 ML을 구현하기 위한 데이터 과학부터 자연어 처리, AutoML, 데이터 스트리밍 분석까지 현장에서 세이지메이커를 바로 적용할 수 있도록 도와주며 보안, 데이터 엔지니어링, 모니터링, CI/CD, 비용 관리와 같은 프로덕션에서 데이터 과학을 제공하는데 필요한 아키텍처 개념을 자세히 설명합니다. 또한 데이터 과학의 가장 최신 기술인 트랜스포머 아키텍처, AutoML, 온라인 학습, 지식 종류, 컴파일, 베이지안 모델 튜닝, 밴딧과 같은 고급 개념도 포함하고 있기 때문입니다.
이 책의 특성은 데이터 수집 및 처리, 머신러닝, 배포 등의 과정을 상세하게 다루며, AWS 서비스와 도구에 대한 명확한 설명과 실용적인 예제, 모델 훈련 및 배포, 보안, 해석 가능성, MLOps 등을 포함한 모델 생성의 모범 사례를 제공하고, AWS에서 데이터 과학 프로젝트의 비용을 절감하고 성능을 향상하는 팁, 아마존 AI와 ML 스택의 실용적인 활용법과 함께 풍부한 실제 사례가 제공되며 이러한 실제 사례를 바탕으로 자연어 처리, 컴퓨터 비전, 사기 탐지, 대화형 디바이스 등 이를 다양하게 적용해볼 수 있다는 점입니다.
구성
Chapter 1: AWS 기반 데이터 과학 소개
Chapter 2: 데이터 과학의 모범 사례
Chapter 3: AutoML
Chapter 4: 클라우드로 데이터 수집하기
Chapter 5: 데이터셋 탐색하기
Chapter 6: 모델 훈련을 위한 데이터셋 준비
Chapter 7: 나의 첫 모델 훈련시키기
Chapter 8: 대규모 모델 훈련과 최적화 전략
Chapter 9: 프로덕션에 모델 배포하기
Chapter 10: 파이프라인과 MLOps
Chapter 11: 스트리밍 데이터 분석과 머신러닝
Chapter 12: AWS 보안
파트별로 나누어 봤을때 1장은 광범위하고 심층적인 아마존 AI와 ML 스택, 굉장히 파워풀하고 다양한 서비스, 오픈 소스 라이브러리 그리고 인프라를 데이터 과학 프로젝트에 접목시키는 방법에 대해 설명하고 있고, 2장은 추천 시스템, 컴퓨터 비전, 사기 탐지, 자연어 이해(NLU), 대화형 디바이스, 인지 검색, 고객 지원, 산업 예측 유지 관리, 홈 자동화, 사물 인터넷(IoT), 의료, 양자 컴퓨팅 등의 실제 사용 사례에 아마존 AI, ML 스택을 적용하는 방법에 대해, 3장은 세이지메이커 오토파일럿의 AutoML을 사용해서 구현하는 방법에 대해, 4~9장은 데이터 수집 및 분석, 피처 선택 및 엔지니어링, 모델 훈련 및 튜닝, 아마존 세이지메이커, 아마존 아테나, 아마존 레드시프트, 아마존 일래스틱 맵리듀스, 텐서플로우 파이토치, 서버리스 아파치 스파크를 활용한 모델 배포와 BERT 기반 자연어 처이(NLP)의 전체 모델 개발 라이프 사이클에 대해, 10장은 세이지메이커 파이프라인, 큐브플로우 파이프라인, 아파치 에어플로우, MLflow, TFX와 함께 MLOps를 사용해 모든 것을 반복 가능한 파이프라인으로 통합하는 방법에 대해, 11장은 아마존 키네시스와 아파치 카프카를 사용해 실시간 데이터 스트림에 대한 실시간 머신러닝, 이상 감지와 스트리밍 분석에 대해, 12장은 AWS IAM, 인증, 권한 부여, 네트워크 격리, 미사용 데이터 암호화, 전송 중 양자 내성 네트워크 암호화, 거버넌스, 감사 가능성을 포함하여 데이터 과학 프로젝트와 워크플로우에 대한 포괄적인 보안 모범 사례에 대해 설명하고 있습니다.
개인적인 생각으로 학습은 데이터 분석가, 데이터 과학자, 데이터 엔지니어, 머신러닝 엔지니어, 연구자, 애플리케이션 개발자, 데브옵스 엔지니어로 취업 및 이직을 희망하시는 분들께서는 우선 클라우드 컴퓨팅의 기본 개념, 파이썬, R, 자바, 스칼라, SQL를 사용한 프로그래밍 기본 기술, 주피터 노트북, 판다스, 넘파이, 사이킷런과 같은 데이터 과학 도구 사용 지식에 대해 학습하신 다음에 1장부터 시작하시면 좋을 것 같고 어느정도 경험이 있으신 분들(데이터 과학자 및 분석가, 엔지니어 2년차~ 또는 개발자 2년차~)부터는 1장은 쭉 훓으시면서 아마존 AI와 ML 스택 및 오픈 소스 라이브러리와 인프라를 데이터 과학 프로젝트에 접목시키는 방법에 대해 파악한다는 방식으로 보시고 2장부터 학습하시는 것이 좋을것 같습니다.
개인적으로 약간의 단점이 어쩌면 욕심일수도 있는게 좀더 많은 실습 예제 및 비즈니스 케이스가 담겨있으면 더 좋았지 않았을까라는 아쉬움이 있습니다.
저의 리뷰를 읽어주셔서 감사합니다. 다음에는 좀더 유용하고 좋은 책으로 더 나은 리뷰를 통해 여러분께 책을 소개시켜드릴 수 있도록 더 노력하겠습니다.
2015년 부터 AI를 공부하고 있지만 아직도 공부 중인 나로서는 이 책의 제목과 목차 그리고 책의 내용은 무척이나 흥미로웠다.
그 이유는 초반에 Machine Learning 기반의 분석과 수요 예측을 할 때는 솔직히 인프라 환경에 대한 중요성 보다는 데이터 분석 포커스에 맞는 데이터 수집 그리고 이를 기반으로 한 분석 프로젝트가 많았었다.
하지만 알파고 이후에 딥러닝이 활성화 되면서 부터는 딥러닝 모델 기반의 솔루션을 제작해야 하는 프로젝트를 수행하게 되었고, 데이터 보안과 맞물려 내부 인프라 장비를 통해 학습을 해야 하는 제약사항이 발생하게 되면서 인프라의 사양이 프로젝트 기간을 수립하는데 중요한 역할을 하게 되었다.
2023년 작금의 상황은 Large Scale Language Model의 시대 무엇보다 중요한 것은 빠르게 학습하여 빠르게 판단할 수 있는 환경을 누가 보유하고 선점하느냐가 가장 중요한 시기가 된 것 같다.
자체 LLM 모델 구축 시에도 무엇보다 선행인건 모델의 빠른 성능 테스트 후 모델의 향상 하지만 이제는 데이터 파이프라인과 데이터 수집은 선결조건인 시대가 되었다.
이에 LLMOPS라는 용어가 탄생하게 되었고 이는 언어 데이터의 메커니즘 및 모델링 메커니즘 기반하여 어떤 식으로 DownStream Task에 효과적으로 적용하여 활용할 수 있는지 까지 고려해야 하는 아키텍처를 구성해야 한다는 측면이라고 생각된다.
이에 AWS에서는 증강 데이터 기반 모델링을 언제 다시 수행해야 하는지에 대하여 오토파일럿을 사용한 AutoML기반의 성능 측정을 통해 재학습할지 여부를 결정하고 이를 비즈니스 로직단에서 활용시에 영향도 분석을 위한 트래킹 실험을 구성한다.
또한 다양한 LLM 오픈 소스 생태계와 연합하여 Foundation Model을 확보하고 이를 기반으로 어떻게 적용될 수 있을지에 대한 엔드포인트 기반 다양항 품질 모니터링을 활용할 수 있는 체계를 수립하였다.
이는 어찌보면 인프라 기반 서비스에 가장 큰 장점이며, 이를 기반으로 빠르게 활용해 보고 적용해 보면서 성능 메트릭을 고도화하는 방법론을 적용하기 위한 선결조건이 인프라라는 것을 의미한다.
이 책은 다양한 분석에 대한 활용을 AWS기반으로 어떻게 작동시키고 사용할 수 있는지에 대하여 전반적으로 다룬 책이다.
지금의 LLM의 열풍을 어떻게 효과적으로 AWS를 활용하여 꾸려갈 수 있는지에 대한 부분도 일부 담고 있다.
이에 데이터 분석을 AWS 클라우드 기반으로 시작하려는 분과 다양한 모델을 빠르게 적용하고, 다양한 데이터 분석 기반하여 모델을 고도화하려는 MLOPS 엔지니어들에게 초석을 다질 수 있는 책이라 생각한다.
아마존 클라우드 컴퓨팅 분야의 베스트셀러인 "AWS 기반 데이터과학" 책을 한빛미디어 서평단으로서 제공받았다.
이 책의 가장 큰 목적은 AWS에서 AI,ML프로젝트를 성공적으로 수행하는 능력을 배양할 수 있다는 것이다.
책의 난이도로 보자면 지식이 전무한 상태로 본다면 굉장히 어렵다.
책의 구성이 굉장히 상세하여, 실무자들에게 많은 도움이 될듯하다
구현이 아니라 이미 만들어진 ChatGPT나 Bard 등의 이미 구현된 인공지능을 사용하는 방법도 있고, 직접 인공지능을 구현하는 방법도 있습니다.
다만 구현하기가 굉장히 어려운 부분이 있어서 보통은 구현되어 있는 인공지능의 API를 사용하는 경우가 많습니다.
하지만 어쩔 수 없는 상황에선 이미 구현해놓은 것이 아닌 새롭게 구현해야 하는 경우가 있을 것입니다.
이런 경우에는 어떻게 해야 할까요?
요즘은 인프라 서비스에서 많은 경우 머신러닝을 하기 위한 서비스를 제공하고 있습니다.
그 중에 하나가 바로 AWS 입니다.
사실 머신러닝과 관련해서 특히 생성형 인공지능과 관련해서 가장 쉽게 구현할 수 있는 곳은 MS에서 제공하는 인프라 서비스인 Azure 입니다.
하지만 원론적으로 머신러닝을 구현하는 방식을 생각하고 있다면 각 인프라 서비스들 마다 장단점이 있겠지만 AWS도 활용하기에 훌륭한 서비스라고 생각합니다.
만약에 AWS를 생각하고 머신러닝을 구현하고자 한다면 이 책을 추천합니다.
이 책은 데이터 수집, 전처리, 저장, 분석, 시각화 및 기계 학습 모델 구축 등 데이터 과학 프로젝트의 주요 단계를 AWS 서비스와 함께 수행하는 방법을 다룹니다. 예를 들어, Amazon S3를 사용하여 데이터를 저장하고 Amazon Redshift 또는 Amazon Athena를 사용하여 데이터를 쿼리하고 분석할 수 있습니다. 또한, Amazon SageMaker를 사용하여 기계 학습 모델을 구축하고 배포할 수 있습니다.
이 책은 데이터 과학 프로젝트를 위한 AWS 서비스를 사용하는 방법을 설명합니다. 이 책을 통해 데이터 과학 프로젝트를 위한 AWS 서비스를 사용하는 방법을 배울 수 있습니다.
이 리뷰 내용은 한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다.
책의 내용이 궁금하다면 [이곳](https://www.hanbit.co.kr/store/books/look.php?p_code=B6134249359)을 통해 확인할 수 있습니다.
AWS(Amazon Web Services)는 아마존에서 제공하는 클라우드 서비스입니다. AWS에서는 단순히 클라우드만 제공하는 것이 아니라 머신러닝 및 인공지능 모델을 개발하고 운영할 수 있는 다양한 서비스를 제공합니다. 'AWS 기반 데이터 과학'은 AWS에서 제공하는 머신러닝 및 인공지능 기능을 활용하여 데이터 과학 파이프라인을 구축하고 모델을 배포하는 방법을 친절하게 설명하는 책입니다.
타겟 독자
이 책의 저자는 AWS에서 근무하는 개발자들이고, 그 중 한 명은 실제로 AWS에서 머신러닝과 인공지능 파이프라인을 구축하는 개발자이기 때문에 누구보다도 AWS에서 제공하는 서비스를 가장 잘 아는 사람일 것이라 생각합니다.
하지만 서비스를 너무 잘 알기 때문인지 초보자에게는 설명이 조금은 불친절하다는 느낌을 받았습니다. AWS의 다양한 서비스들을 설명하면서도 UI를 거의 보여주지 않았고, 처음에 환경 설정을 어떻게 해야 하는지, 어떻게 서비스를 사용해야 하는지에 대한 방법은 거의 생략하고 있었습니다. 이미 서비스를 사용하고 있는 사람들에게 어떻게 해야 더 효율적으로 AWS의 서비스를 사용하는지를 설명하는 내용이 주를 이루기 때문에 초보자보다는 이미 AWS의 세이지 메이커나 키네시스 등을 사용하고 있는 사람, 데이터 과학을 충분히 공부한 데이터 과학자, 데이터 분석가, 데이터 엔지니어, 머신러닝/인공지능 엔지니어, 데브옵스 엔지니어 등에게 유용한 책일 것 같습니다.
주요 내용
이 책에서는 "인공지능과 머신러닝 실무자가 AWS에서 데이터 과학 프로젝트를 성공적으로 빌드하고 배포하는 방법"을 다루고 있습니다. 총 12개의 장으로 구성된 'AWS 기반 데이터 과학'은 1-3장까지는 AWS 세이지메이커의 포괄적인 사용 방법과 사례를 다루고 4장부터 9장까지 데이터 과학 프로젝트를 빌드하고 배포하는 과정을 다룹니다. 10장에서는 파이프라인을 만드는 법, 11장에서는 실시간 데이터를 다루는 스트리밍 분석, 마지막 12장에서는 보안을 다룹니다.
장점
1. 소스 코드 제공
실제 프로젝트에서 이루어지는 일들을 다루기 때문에 데이터 과학 또는 ML/AI 프로젝트를 실제 배포하는 업무를 처음 담당하는 사람들에게는 큰 도움이 될 수 있는 책입니다. 실제 사례를 기반으로 프로젝트를 설명하고, 소스 코드를 제공해 주기 때문에 실무에 적용할 때 유용할 것 같습니다.
코드와 결과 제공
2. 이미지와 표 제공
또한 글로만 설명해서는 이해하기 어려운 내용은 이미지나 표로 다시 한번 정리해 주기 때문에 이해가 되지 않을 때는 이미지나 표를 통해 직관적으로 이해할 수 있습니다.
글로 설명한 것을 이미지로 표현
3. 다양한 실제 사례 제공
각 장은 실제 사례를 통해 어떻게 서비스를 이용해야 하는지를 설명합니다. 2-3장에서는 다양한 사례를 짧지만 핵심적인 내용을 다루고 있고, 4장부터는 아마존 고객 리뷰라는 하나의 사례를 이어가면서 각 단계에서 세이지메이커를 어떻게 사용하는지를 순차적으로 보여줍니다. 분야가 다른 실무자를 위해서인지 자연어처리의 역사와 BERT를 자세히 설명해 주기도 합니다.
아마존 리뷰를 BERT 모델로 분류하는 사례
4. 비용 절감과 성능 향상을 위한 방법 제공
실무자로서는 비용 절감과 성능 향상을 항상 고민할 수 밖에 없습니다. 이 책에서는 매 장마다 실무자로서의 고민인 성능 향상과 비용 절감을 어떻게 할 수 있는지 다양한 방법을 제시해 주기 때문에 실무에 그 방법들을 도입해 보면서 비용 절감과 성능 향상을 모두 꾀할 수 있을 것 같습니다.
아쉬움
이 책의 타겟이 아닌 처음 AWS 서비스를 이용하려는 사람들에게 이 책의내용은 이해하기 어려울 것 같습니다. 특히 1-3장에서는 이미지보다는 글이 많고, AWS의 서비스 용어가 많기 때문에 이해하기가 쉽지는 않았습니다. 이전에 AWS 관련된 책을 보았기 때문에 이해하기 어렵지 않을 것이라고 생각했지만 충분히 용어와 서비스를 이해하지 못한 저에게는 이해하기 조금 어려웠고, 그로 인해 집중하기 쉽지 않았습니다.
이 책의 타겟이 초보자가 아닌 실무자이기 때문에 친절하지 않음은 이해할 수 있으나 AWS를 처음 사용하는 실무자를 위해 조금 더 친절하게 설명해 주었으면 어땠을까 하는 생각이 듭니다.
실무에서 실시간으로 쌓이는 대용량 데이터를 사용해서 실무 프로젝트를 진행한다면 클라우드 환경을 빼놓고 일하기가 어렵다. 이 책은 여러 클라우드 제품군 중 AWS를 기반으로 쓰여졌다.
데이터과학에 대한 어느정도 기본 이해가 있는 상태에서 AWS제품군을 활용방안을 제시하고 있기 때문에 데이터 과학에 대한 기초 소양이 필요한 책이기도 하다.
현업에서 AWS의 제품군을 활용하여 어떻게 비즈니스를 해야하는지에 대한 구체적인 사례를 함께 제시하고 있다. 단순히 알고리즘 혹은 클라우드 제품에 대한 소개가 아니라 제품군을 활용하여 실제 비즈니스에 어떻게 활용되는지에 대한 사례가 있어야 현업에 어떻게 적용할지 아이디어를 얻을 수 있는데 그런 점에서 이 책이 좋은 가이드 역할을 한다.
AWS는 제품군이 다양하고 복잡해서 콘솔을 열면 어디부터 작업해야할지 난감한데 이 책을 활용하여 데이터 과학 프로젝트를 어떻게 구축하고 배포해야하는지 상세하게 배울 수 있다.
실제 사례를 바탕으로 자연어처리, 컴퓨터 비전, 사기 탐지 등 비즈니스에 접목할 수 있는 예시라 아이디어를 얻기 좋다.
아마존 ML 스택을 통해 세이지메이커 오토파일럿의 AutoML을 사용한 사례를 통해 복잡한 제품군에 대한 활용법을 찾아볼 수 있다. 머신러닝 모델을 반복가능한 MLOps 파이프라인으로 통한합는 방법, 아마존 키네시스와 아파치 카프카용 아마존 관리형 스트리밍을 활용하여 실시간 데이터 스트림에 머신러닝, 이상탐지, 스트리밍 분석을 적용한 사례를 다룬다.
추천시스템, 컴퓨터비전, 사디탐지, 자연어이해, 대화형 디바이스, 인지검색, 고객지원, 산업예측 유지관리, 홈자동화, 사물인터넷 등 적용해 볼 수 있는 다양한 사례를 제공하고 있기 때문에 데이터 과학 프로젝트를 어떻게 활용해야 하는지에 대한 힌트를 얻을 수 있는 책이기도 하다.
데이터 수집 및 분석, 피처 선택 및 엔지니어링, 모델 훈련 및 튜닝, 아마존 세이지메이커, 아마존 아데나, 레드시프트, 일레스틱 맵리듀스(EMR), 텐서플로, 파이토치, 서비리스 아파치 스파크 등 다루는 기술이 방대하고 데이터 과학을 위한 AWS의 대부분의 제품군을 다루고 있다.
AWS 제품군 위주로 다루고 있기는 하지만 비즈니스 사례에 대한 질문을 곳곳에서 적절하게 던져주고 있기 때문에 실제 비즈니스에서 어떤 고민을 하고 활용해야하는지 생각할 지점을 제공해 준다는 점도 좋다.
예를 들어 2015년에 동일한 상품에 대해 2개 이상의 리뷰를 작성한 고객은 누구인가? 각 상품의 평균 별점은 몇 점인가?와 같은 질문을 통해 현업에서 고민할만한 질문을 어떻게 해결해 나가야할지 현업의 고민을 녹이기 위한 노력이 보이는 책이기도 하다. AWS 제품군 활용 뿐만 아니라 이런 질문을 통해 비즈니스 사례에서 어떻게 활용하면 좋을지 함께 고민해 볼 수 있는 책이다.
"aws 기반 데이터 과학" 책은 AWS를 활용하여 데이터 과학을 수행하는 방법과 AWS의 다양한 서비스를 활용하여 데이터 분석 및 머신러닝 프로젝트를 구축하는 방법에 대해 다루고 있는 도서입니다.
저는 'AWS data analytics 자격증'을 취득하면서 실제 AWS 서비스와 데이터 분석 솔루션이 어떻게
실제로 적용될 지 공부를 많이 했는데, 제가 많이 고민하고 어려웠던 부분에 대한 해답을
쉽고 빠르게 제시해주는 책이였습니다.
가장 기초가 되는 AWS 기초 서비스 시작부터 실제 분석하는데 활용되는 MLOps 파이프라인에 대한ㅅ ㅓㄹ명까지 기초 -> 심화 과정까지 많은 내용을 다루어서 좋았습니다.
그래서 IT 데이터 분석에 대해 관심이 있으신 분들부터 심화된 내용을 원하는 분들까지 모두 읽으시기 좋습니다.
MLOps 라는 방법론을 통해서 기계 학습 프로젝트를 보다 효율적으로 관리하고, 모델의 배포와 운영을 용이하게 만들어주는 내용에 대한 부분이 가장 인상깊었고 실제로 MLOps 구축에 대한 내용을 다뤄주니
엔지니어로서 업무상 많은 도움이 되었습니다. MLops CI/CD (Continuous Integration/Continuous Deployment) 워크플로우를 기계 학습에 적용하여 개발과 배포 사이클을 단축시키고, 지속적인 통합과 배포를 가능하게 하는 부분에 대한 내용이 자세하게 다루어집니다.
데이터 과학은 우리의 삶과 어떠한 연관이 있을까요?
개인화된 경험과 관련 있다 할 수 있습니다.
맞춤형 서비스와 제품은 우리의 선호도, 관심사, 행동 패턴을 분석해 만들어집니다.
모든 산업에 걸쳐 있는 데이터 과학과 관련이 있습니다.
데이터 과학을 잘 알려주는 책을 소개하려 합니다.
소개 해드릴 책은 'AWS 기반 데이터 과학'입니다.
사람들은 AWS에서 제공하는 성공적인 데이터 과학 프로젝트에 관심을 갖습니다.
그 이유는 프로젝트 비용은 줄이고 성능은 최적화하고 싶기 때문입니다.
◆ 여러 산업에서 도입하는 추천 시스템
상품 추천 모범 사례로 아마존 시스템이 많이 언급됩니다.
쇼핑 외에도 스트리밍 서비스, 음악 플랫폼, 소셜 미디어 산업에서도 추천 시스템을 개발합니다.
고객 만족도를 높이면 고객이 대신 홍보해 주면서 매출 증대에도 기여할 수 있습니다.
아마존은 사용자의 구매 이력, 평가, 검색 기록 등을 수집해 사용자에게 필요한 상품을 추천해 줍니다.
내부 알고리즘은 복잡하겠지만 추천 시스템을 잘 만들면 구매 확률과 만족도도 높일 수 있습니다.
기업은 사용자의 관심사 정보를 통해 새로운 전략을 세우고 서비스를 만들게 됩니다.
◆ 비즈니스 전략을 세우는 수요 예측
기업과 조직은 제품과 서비스를 만들기 전 수요를 먼저 조사합니다.
수요 예측을 통해 비즈니스 전략을 수립하는데요.
과거의 패턴과 트렌드를 분석해 미래 수요를 예측하게 됩니다.
예측한 데이터를 토대로 재고관리, 생산계획 마케팅 전략을 최적화할 수 있습니다.
수요 예측 데이터는 여러 산업에서 중요한 의사 결정 도구로 사용하는데요.
소매, 제조, 로지스틱스, 여행, 호텔, 금융 등 다양한 분야에서 수요를 분석합니다.
전략은 계절, 지역, 고객 세분화 등을 고려해 모델을 만들고 모델 데이터를 활용해 판매량을 예측할 수 있습니다.
데이터 과학은 과거 생산 데이터, 시장동향, 경제 지표를 고려해 생산을 최적화하고 비용을 줄이는 역할을 합니다.
세이지메이커는 확장성, 모델 관리, 배포 및 모니터링 등 다양한 장점이 있습니다.
단점으론 아마존 클라우드 플랫폼에 종속되는 건데요.
아마존 환경을 쓰려고 할 경우 클라우드는 초기설정과 구성의 복잡성 추가 비용도 고려해야 합니다.
끝으로 이 책은 아마존 세이지메이커를 사용해 AI 서비스와 Auto ML 활용법을 잘 알려줍니다.
클라우드 기반이므로 편리하고 다양한 AI 서비스를 사용해 볼 수 있습니다.
세이지 메이커는 제조업체에서 제품 품질 관리, 예측 유지보수 등에 기계 학습을 적용합니다.
의료분야에서도 의료 영상분석, 질병 예측 및 생체 신호 분석에 활용됩니다.
금융기관에서도 사기 탐지, 신용 스코어링 등 기계학습을 적용할 수 있습니다.
아마존 클라우드에 관심 있는 분들에게 이 책을 추천합니다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
요즘 현업에서 AWS Lambda를 작업하며 데이터 엔지니어의 업무를 진행하고 있다. 때마침, 한빛미디어 리뷰 이벤트에 해당 책이 후보에 올라와 있었고 나는 당연히 이 책을 고를 수 밖에 없었다.
물론 Lambda 뿐만 아니라 다른 다양한 내용을 포함하고 있겠지만, 당장 내가 사용하는 lambda에 대한 해답을 얻고자 선택한 것도 있었다.
먼저 소개에 앞서, 목차부터 소개하고자 한다.
목차
CHAPTER 1 AWS 기반 데이터 과학 소개 CHAPTER 2 데이터 과학의 모범 사례 CHAPTER 3 AutoML CHAPTER 4 클라우드로 데이터 수집하기 CHAPTER 5 데이터셋 탐색하기 CHAPTER 6 모델 훈련을 위한 데이터셋 준비 CHAPTER 7 나의 첫 모델 훈련시키기 CHAPTER 8 대규모 모델 훈련과 최적화 전략 CHAPTER 9 프로덕션에 모델 배포하기 CHAPTER 10 파이프라인과 MLOps CHAPTER 11 스트리밍 데이터 분석과 머신러닝 CHAPTER 12 AWS 보안
크게 위와 같이 12가지 큰 목차로 책의 내용을 풀어가고 있다.
큰 챕터들에서는 보이지 않지만, 소제목들에서는 AWS Lambda와 SageMaker 그리고 Glue 등에 대해서 설명들이 주로 이루어졌다.
전체적인 파이프라인은 크게 3단계로 나뉘는 것으로 제안하고 있고 아래와 같이 나와있다.
1. 데이터 준비
- 데이터 수집
- 데이터 분석 - 데이터 변환 - 데이터 검증 - 훈련데이터 생성
2. 모델 훈련 및 튜닝 - 모델 훈련 - 모델 튜닝
3. 배포와 모니터링 - 배포 - 서빙 - 모니터링 - 로깅
해당 워크플로우를 구현할 수 있도록 여러가지 예시들을 보여주는데, 그 중 airflow도 포함되어 있었다.
(최근 공부중이라 반가운 부분이었다.)
그리고, 처음 사용하는 유저들을 위해 미리 앞서 말해주는 부분이 바로 '비용'에 관련된 부분이었다.
클라우드 컴퓨팅 및 클라우드 서버를 사용하면 대부분 유료 서비스인 것을 알 수 있다.
(물론, Colab은 아직까지 무료로 제공 되는 부분이 있기는 하지만..)
이러한 유료 서비스에서 어떻게 하면 과금이 되는지에 대한 구조에 대해서 설명을 해주었으며, 비용을 절감할 수 있는 효율적인 처리에 대해 간략적인 가이드가 제공되고 있다.
모델 파이프라인 관련해서 가장 유용하게 사용되는 AutoML 은 SageMaker에서 사용할 수 있다고 한다.
데이터 적재 관련해서는 데이터 레이크를 손쉽게 구축할 수 있는 레이크 포메이션을 소개하고 있으며, 글루를 이용하여 데이터 카탈로그 작업도 가능한 것을 확인할 수 있었다.
이와 같이 책 앞에서는 각각 파이프라인 별로 어떠한 기능들을 이용하여 구현할 수 있는지 설명을 해주었다.
해당 도서에서 가장 좋았던 점을 느낀것은 바로 모범 사례 파트였다.
- 아마존 세이지 메이커와 텐서플로를 이용한 추천 시스템 생성하기
- 아마존 세이지 메이커와 아파치 스파크로 추천 시스템 생성하기
등 다양한 사례들이 존재했고, 사례 소개 뿐만 아니라 참고할 수 있는 코드까지 같이 내용에 포함되어 너무 좋은 가이드가 될 수 있을 것이라 생각되었다.
그 이후로는 세이지 메이커로 AutoML 사용하는 법과 아테나를 통한 데이터 적재 등 다양한 코드 기반으로 한 가이드들을 보여주었다.
해당 도서는 코드를 기반으로 여러가지 사례들을 안내해주고 가이드로 참고할 수 있는 부분이 많아 초보자 및 실무자들에게 굉장히 좋은 이정표로 쓰일 것으로 기대가 되었다.
AWS 를 이용해서 어떻게 파이프 라인을 구축하고 사용하는지 공부해보려고 이 책을 읽기 시작했다. 그런데 이책.. 생각보다 읽기가 쉽지 않다. 처음에는 챕터 1에서 AWS 기반 데이터 과학에 대한 소개가 이루어지고, 챕터 2에서는 AWS를 활용한 모범사례가 소개되어있다. 그러나 이 부분에서는 다양한 기술과 내용들이 많이 다뤄져서 진도를 나가기가 어려웠다. 특히, AWS에 대한 기반 지식이 부족한 나에게는 쉽게 이해되지가 않았다. 그래서 생각해 보니 챕터 3부터 시작해서 주요 기술이 자세히 설명되어 있는 부분부터 읽는 것도 좋을것 같았다. 책을 읽으면서 중요한 기술들을 학습하고, 해당 내용을 실습하며 익히다 보면 보다 쉽게 파이프 라인 구축에 도움이 될것이다.
이 책을 읽으면서 가장 큰 단점은 이미지나 캡쳐 화면과 같은 시각적인 자료가 부족하다는 점이다. 텍스트로만 설명 되어 있어 설정 값들과 텍스트가 의미하는 것들을 이해하는 데에 어려움이 많았다. 책에 시각적인 자료를 추가하거나 관련된 예시와 함께 설명해 주면 내용을 보다 쉽게 이해할 수 있을 것이다. 결론적으로, 이 책은 AWS에 대한 기반 지식이 있는 독자들에게 더 유익하게 다가갈 수 있을것이다. 그리고 책을 공부하기 위해서는 먼저 AWS 에 대한 기반 지식을 충분히 습득한 후에 읽는것이 좋을것 같다.