책소개
관찰 가능성은 복잡한 최신 시스템의 소프트웨어를 구축, 수정, 이해하는 데 매우 중요합니다. 관찰 가능성을 채택한 팀은 코드를 신속하고 자신 있게 배포할 수 있으며, 이상값과 비정상적인 동작을 식별하고, 모든 사용자의 경험을 훨씬 더 잘 이해할 수 있습니다.
이 책은 관찰 가능성의 개념과 중요성을 설명하며, 현대 소프트웨어 시스템 관리에서 왜 관찰 가능성이 필요한지를 다룹니다. 또한, 관찰 가능성과 모니터링의 차이점을 분석하고 각 접근 방식의 장단점을 비교합니다. OpenTelemetry와 같은 도구를 사용하여 관찰 가능성 시스템을 구현하고 데이터 기반 문제 해결 방법을 소개하며, 실제 사례에 어떻게 적용되는지도 알아봅니다. 마지막으로 관찰 가능성을 조직에 도입하고 확산시키는 사회적, 문화적 접근 방법에 대해 다룹니다.

저자소개

목차
PART 1 관찰 가능성으로 가는 길
chapter 1 관찰 가능성이란?
_1.1 관찰 가능성의 수학적 정의
_1.2 소프트웨어 시스템에 대한 관찰 가능성 적용
_1.3 소프트웨어를 위한 관찰 가능성에 대한 잘못된 특성화
_1.4 왜 지금 관찰 가능성인가?
__1.4.1 이것이 정말 최선의 방법인가?
__1.4.2 메트릭과 모니터링이 충분하지 않은 이유
_1.5 메트릭을 이용한 디버깅과 관찰 가능성을 이용한 디버깅
__1.5.1 카디널리티의 역할
__1.5.2 디멘셔널리티의 역할
_1.6 관찰 가능성을 이용한 디버깅
_1.7 현대적인 시스템을 위한 관찰 가능성
요약
chapter 2 관찰 가능성과 모니터링의 디버깅은 어떻게 다를까?
_2.1 모니터링 데이터를 활용한 디버깅
__2.1.1 대시보드를 이용한 문제 해결
__2.1.2 직관을 통한 문제 해결의 한계
__2.1.3 사후 대응적일 수밖에 없는 기존 모니터링
_2.2 관찰 가능성을 통한 더 나은 디버깅
요약
chapter 3 관찰 가능성 없이 확장하며 배운 교훈
_3.1 메타가 인수한 MBaaS 기업 Parse
_3.2 Parse에서 경험했던 확장성
_3.3 현대적 시스템으로의 진화
_3.4 현대적 관행으로의 진화
_3.5 Parse의 전환 사례
요약
chapter 4 관찰 가능성은 어떻게 데브옵스, Sre, 클라우드 네이티브를 연결하는가
_4.1 클라우드 네이티브, 데브옵스, SRE에 대한 간단한 소개
_4.2 관찰 가능성: 디버깅의 과거와 오늘
_4.3 관찰 가능성을 통한 데브옵스와 SRE 프랙티스의 강화
요약
PART 2 관찰 가능성 기초
chapter 5 정형화된 이벤트: 관찰 가능성의 기본 구성 요소
_5.1 정형화된 이벤트를 이용한 디버깅
_5.2 메트릭을 기본 구성 요소로 사용하기 어려운 이유
_5.3 기존 로그를 기본 구성 요소로 사용하기 어려운 이유
__5.3.1 비정형 로그
__5.3.2 정형화된 로그
_5.4 디버깅 시 유용한 이벤트 속성
요약
chapter 6 이벤트를 추적으로 연결하기
_6.1 분산 추적이란 무엇이고 왜 중요한가?
_6.2 추적을 구성하는 컴포넌트
_6.3 어렵게 추적 계측하기
_6.4 추적 스팬에 사용자 정의 필드 추가하기
_6.5 이벤트를 추적으로 연결하기
요약
chapter 7 Opentelemetry를 이용한 계측
_7.1 계측이란?
_7.2 오픈 계측 표준
_7.3 코드를 이용한 계측
__7.3.1 자동 계측 시작하기
__7.3.2 사용자 정의 계측 추가하기
__7.3.3 백엔드 시스템으로 계측 데이터 전송하기
요약
chapter 8 관찰 가능성 확보를 위한 이벤트 분석
_8.1 알려진 조건 기반의 디버깅
_8.2 디버깅의 제1원칙
__8.2.1 핵심 분석 루프 사용하기
__8.2.2 핵심 분석 루프의 무차별 대입 자동화
_8.3 AIOps의 약속에 대한 오해
요약
chapter 9 관찰 가능성과 모니터링의 공존
_9.1 모니터링이 적합한 사례
_9.2 관찰 가능성이 적합한 사례
_9.3 대상 시스템, 소프트웨어에 따른 고려 사항
_9.4 조직의 요구사항 평가
__9.4.1 예외 무시할 수 없는 인프라 모니터링
__9.4.2 실전 예시
요약
PART 3 팀을 위한 관찰 가능성
chapter 10 관찰 가능성 사례 적용하기
_10.1 커뮤니티 그룹 참여하기
_10.2 가장 큰 고민거리에서 시작하기
_10.3 구축보다 구매
_10.4 반복을 통한 계측 구체화
_10.5 기존의 노력을 최대한 활용하기
_10.6 관찰 가능성 적용의 최종 관문
요약
chapter 11 관찰 가능성 주도 개발
_11.1 테스트 주도 개발
_11.2 개발 생애주기 내에서의 관찰 가능성
_11.3 디버그 지점의 결정
_11.4 마이크로서비스 시대의 디버깅
_11.5 계측이 관찰 가능성 도입을 촉진하는 방법
_11.6 관찰 가능성의 조기 투입
_11.7 소프트웨어 배포 가속화를 위한 관찰 가능성 활용
요약
chapter 12 신뢰성을 위한 SLO의 활용
_12.1 전통적 모니터링 접근 방법이 낳은 알람에 대한 피로감
_12.2 알려진 무지만을 위한 임계치 기반의 알람
_12.3 중요한 것은 사용자 경험이다
_12.4 SLO란 무엇인가?
__12.4.1 SLO 기반의 신뢰성 있는 알람
__12.4.2 사례 연구: SLO 기반의 알람 문화 변화
요약
chapter 13 SLO 기반 알람 대응과 디버깅
_13.1 오류 예산이 소진되기 전에 경고하기
_13.2 슬라이딩 윈도우를 이용한 시간 범위 설정
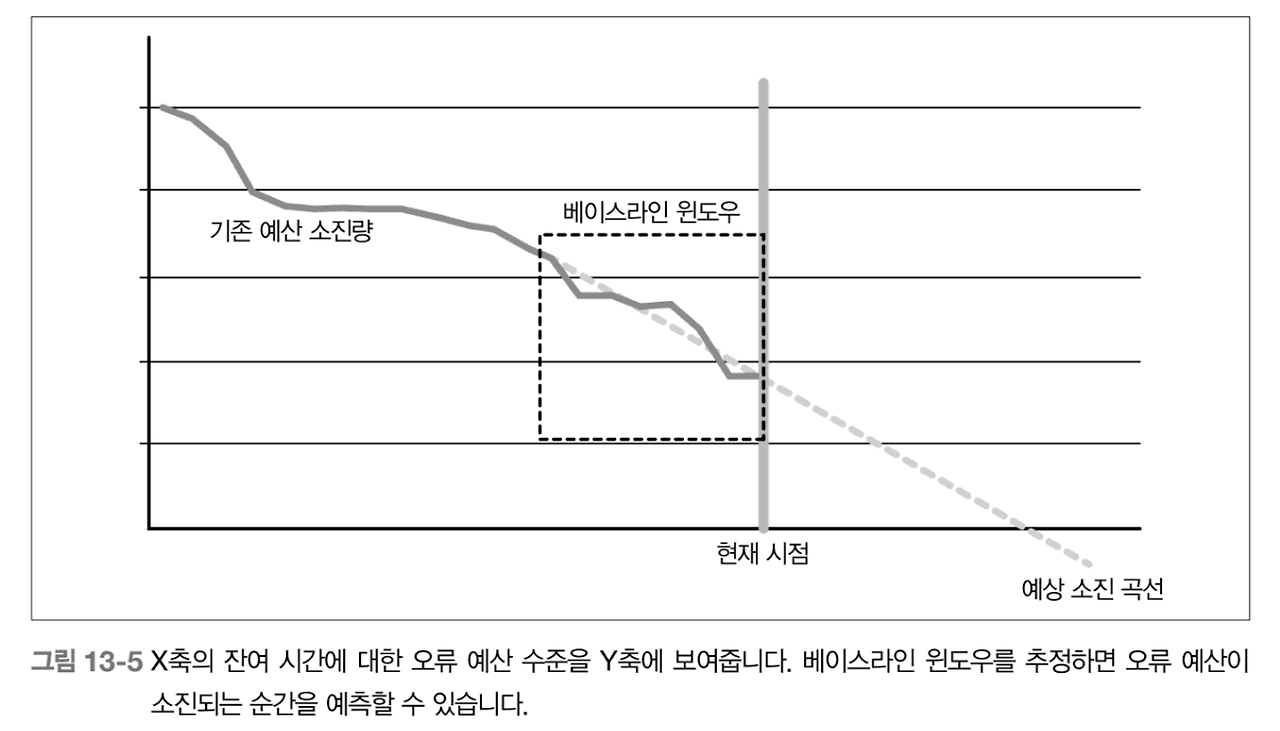
_13.3 오류 예산 소진 알람 생성을 위한 예측
__13.3.1 룩어헤드 윈도우
__13.3.2 베이스라인 윈도우
__13.3.3 SLO 소진 알람 대응하기
_13.4 관찰 가능성 데이터와 시계열 데이터를 이용한 SLO 측정의 차이
요약
chapter 14 관찰 가능성과 소프트웨어 공급망
_14.1 슬랙이 관찰 가능성을 도입한 이유
_14.2 계측: 공유 클라이언트 라이브러리와 디멘션
_14.3 사례 연구: 소프트웨어 공급망에 관찰 가능성 적용하기
__14.3.1 도구를 이용한 문맥의 이해
__14.3.2 실행 가능한 알람 내장하기
__14.3.3 변경사항 이해하기
요약
PART 4 규모에 맞는 관찰 가능성 시스템 구축
chapter 15 투자 회수 관점에서 본 구축과 구매
_15.1 관찰 가능성의 ROI 분석 방법
_15.2 자체 구축 비용
__15.2.1 무료 소프트웨어 사용의 숨겨진 비용
__15.2.2 자체 구축의 장점
__15.2.3 자체 구축의 위험성
_15.3 상용 소프트웨어 실제 도입 비용
__15.3.1 상용 소프트웨어 도입의 숨겨진 재무적 비용
__15.3.2 상용 소프트웨어 도입의 숨겨진 비재무적 비용
__15.3.3 상용 소프트웨어 도입의 이점
__15.3.4 상용 소프트웨어 구매의 위험성
_15.4 자체 구축과 상용 소프트웨어 도입은 옳고 그름의 문제가 아니다
요약
chapter 16 효율적인 데이터 스토리지
_16.1 관찰 가능성을 위한 기능적 요구사항
__16.1.1 관찰 가능성에 부적합한 시계열 데이터베이스
__16.1.2 다른 데이터 저장소 후보들
__16.1.3 데이터 스토리지 전략
_16.2 사례 연구: 허니컴 리트리버의 구현
__16.2.1 시간 단위로 데이터 파티셔닝하기
__16.2.2 세그먼트 내에 열별로 데이터 저장하기
__16.2.3 쿼리 작업 수행하기
__16.2.4 추적 쿼리하기
__16.2.5 실시간으로 데이터 쿼리하기
__16.2.6 티어링을 활용한 비용 효율적인 쿼리 처리
__16.2.7 병렬 처리를 통해 빠르게 만들기
__16.2.8 높은 카디널리티 다루기
__16.2.9 확장성과 내구성 전략
__16.2.10 효율적인 자체 데이터 스토어 구축을 위한 고려 사항
요약
chapter 17 샘플링: 비용과 정확성 모두를 위한 선택
_17.1 데이터 수집을 정제하기 위한 샘플링
_17.2 샘플링에 대한 다양한 접근 방법
__17.2.1 고정 확률 샘플링
__17.2.2 최신 트래픽 볼륨 기반의 샘플링
__17.2.3 이벤트 콘텐츠(키) 기반 샘플링
__17.2.4 키, 메서드 조합을 통한 샘플링
__17.2.5 동적 샘플링 옵션 선택
__17.2.6 추적에 대한 샘플링 결정 시점
_17.3 샘플링 전략의 코드화
__17.3.1 기본 시나리오
__17.3.2 고정 비율 샘플링
__17.3.3 샘플링 비율의 기록
__17.3.4 일관성 있는 샘플링
__17.3.5 목표 비율 샘플링
__17.3.6 하나 이상의 정적 샘플링 비율 사용하기
__17.3.7 키와 목표 비율을 이용한 샘플링
__17.3.8 많은 키를 지원하는 동적 비율 샘플링
__17.3.9 여러 가지 샘플링 방법의 동시 적용
요약
chapter 18 파이프라인을 이용한 원격 측정 관리
_18.1 원격 측정 파이프라인의 속성
__18.1.1 라우팅
__18.1.2 보안과 규제 준수
__18.1.3 워크로드의 격리
__18.1.4 데이터 버퍼링
__18.1.5 용량 관리
__18.1.6 데이터 필터링 및 증강
__18.1.7 데이터 변환
__18.1.8 데이터 품질과 일관성 보장
_18.2 원격 측정 파이프라인의 관리 자세히 살펴보기
_18.3 원격 측정 파이프라인 관리 시 당면 과제
__18.3.1 성능
__18.3.2 정확성
__18.3.3 가용성
__18.3.4 신뢰성
__18.3.5 격리
__18.3.6 데이터 신선도
_18.4 사례 연구: 슬랙에서의 원격 측정 관리
__18.4.1 메트릭 집계
__18.4.2 로그와 추적 이벤트
_18.5 오픈소스 대안들
_18.6 원격 측정 파이프라인 관리: 구축할 것인가 구매할 것인가
요약
PART 5 관찰 가능성 문화의 확산
chapter 19 관찰 가능성 비즈니스 사례
_19.1 변화에 대한 사후 대응적인 접근 방법
_19.2 관찰 가능성의 투자 수익률
_19.3 변경에 대한 적극적인 접근 방법
_19.4 사례로서의 관찰 가능성 소개
_19.5 적절한 도구를 이용한 관찰 가능성 실천
__19.5.1 계측
__19.5.2 데이터 저장소와 분석
__19.5.3 도구의 출시
_19.6 충분한 관찰 가능성을 확보했는지 인식하기
요약
chapter 20 관찰 가능성의 이해관계자와 조력자
_20.1 비엔지니어링 관찰 가능성 요구사항의 식별
_20.2 실무에서 관찰 가능성 조력자 만들기
__20.2.1 고객 지원팀
__20.2.2 고객 성공팀과 제품팀
__20.2.3 영업팀과 경영팀
_20.4 관찰 가능성 도구와 비즈니스 인텔리전스 도구의 차이점
__20.4.1 쿼리 실행 시간
__20.4.2 정확도
__20.4.3 최신성
__20.4.4 데이터 구조
__20.4.5 시간 범위
__20.4.6 일시성
_20.5 실무에서 관찰 가능성과 BI 도구 함께 사용하기
요약
chapter 21 관찰 가능성 성숙도 모델
_21.1 성숙도 모델에 대한 기본적인 이해
_21.2 관찰 가능성 성숙도 모델이 필요한 이유
_21.3 관찰 가능성 성숙도 모델
_21.4 관찰 가능성 성숙도 모델의 기능들
__21.4.1 시스템 실패에 대한 탄력성
__21.4.2 완성도 높은 코드의 배포
__21.4.3 소프트웨어 복잡도와 기술 부채의 관리
__21.4.4 예측 가능한 릴리스
__21.4.5 사용자 동작의 이해
_21.5 조직을 위한 관찰 가능성 성숙도 모델 적용
요약
chapter 22 관찰 가능성의 미래
_22.1 관찰 가능성의 과거와 현재
_22.2 보충 자료
_22.3 관찰 가능성의 미래
출판사리뷰
현대 소프트웨어 개발 및 관리의 핵심 전략과 도구
『데브옵스 엔지니어를 위한 실전 관찰 가능성 엔지니어링』은 관찰 가능성이 무엇인지, 관찰 가능한 시스템을 어떻게 식별하는지, 현대적인 소프트웨어 시스템을 관리할 때 관찰 가능성 기반의 디버깅이 적합한 이유를 알아봅니다. 그와 함께 관찰 가능성의 여러 가지 기술적 측면을 살펴보며, 기존 모니터링 체계와의 공존 방법에 대해 다룹니다. 또한 관찰 가능성을 처음 도입할 때 직면하게 되는 어려움과 일하는 방식의 변화 등 다양한 환경에서 겪게 되는 관찰 가능성의 사례와 문제점을 알아봅니다. 마지막으로, 관찰 가능성 문화를 조직에 채택하는 접근 방법을 논의하며, 조직 전반에 걸쳐 관찰 가능성 채택을 위해 이해해야 하는 문화적 메커니즘에 대해 설명합니다.
오탈자 등록