IT/모바일
by 팀 오라일리(Tim O"Reilly)와 존 바텔(John Battelle), 홍형경 역
5년 전, 우리는 간단한 아이디어를 근거로 컨퍼런스를 개최했었고, 이제 그 아이디어는 하나의 운동으로 발전했다. 애초에 웹 2.0 컨퍼런스(현재는 웹 2.0 서밋)는 닷컴 붕괴 후 길을 잃고 헤매던 산업계에 자신감을 회복시켜 주기 위한 목적으로 기획되었다. 이전에 주장했듯이, 웹은 완성된 것이 아니며, 컴퓨터 애플리케이션과 서비스로 대표되는 문화변혁 세대를 위한 강력한 플랫폼으로 거듭나고 있는 중이다.
첫 번째 프로그램에서, 우리는 닷컴 붕괴 후 매우 처참하게 실패한 기업이 있었던 반면, 일부 기업들은 어떻게 살아남게 되었는지에 대한 질문을 받았다. 또한 신생성장 기업들에 대한 연구를 진행하면서, 그들이 그렇게 빨리 성장하는 이유에 대해서도 질문을 받았다. 그리고 이러한 질문에 대한 답을 구하는 과정은 새로운 플랫폼 상에서의 비즈니스 규칙을 이해하는데 도움이 되었다. 우리의 통찰력 중 으뜸은 "플랫폼으로서의 네트워크"인데, 이는 단순히 네트워크를 경유하여 예전의 애플리케이션을 제공하는 것("서비스로서의 소프트웨어") 이상을 의미한다. 즉, 문자 그대로 더 많은 사람들이 사용할 수 있도록 개선하고, 사용자들을 더 확보할 뿐만 아니라 사용자들의 기여를 통해 만들어지고 그들로부터 배우는 네트워크 효과를 이용하는 애플리케이션을 구축하는 것을 의미한다.
구글과 아마존에서 위키피디아, 이베이 그리고 크레이그리스트(craigslist)까지, 우리는 소프트웨어에 의해 실현되었지만, 밀접하게 연결된 사용자 커뮤니티와의 협력을 통해 창조된 가치를 목격했다. 그 이후로, 유튜브, 페이스북 그리고 트위터와 같은 강력해진 새로운 플랫폼들이 새로운 방식으로 동일한 통찰력을 여실히 보여줬다. 웹 2.0은 바로 집단지성을 활성 및 활용하는 것에 대한 모든 것을 의미한다.
집단지성 애플리케이션은 사용자들이 생성하는 엄청난 양의 데이터에 대한 실시간 응답, 이해, 관리에 의존하고 있다. 최근 출현하고 있는 인터넷 운영체제의 "서브시스템"들은 점점 더 데이터 서브시스템이 되어 가고 있는데, 이는 위치나 사람, 사물, 장소의 식별, 그리고 이들을 함께 엮은 의미의 실타래로 구성되어 있다. 이것은 경쟁 우위를 확보하는 새로운 수단으로 이끌고 있다: 데이터는 이제 컴퓨터 애플리케이션의 차세대 "인텔 인사이드"가 되었다.
오늘날, 우리는 이러한 통찰력이 제대로 방향을 잡았을 뿐만 아니라, 2004년에는 상상만 가능했던 영역에 적용되고 있다는 점을 깨닫고 있다. 스마트폰 혁명은 웹을 사무실에서 호주머니 속으로 이동시켰다. 집단지성 애플리케이션은 이제 더 이상 키보드를 두드리는 인간에 의해서가 아닌, 점점 더 센서에 의해 구동되고 있다. 이동전화나 카메라는 애플리케이션을 위한 눈과 귀 역할을 하고 있다; 동작 및 위치 센서는 우리가 어디에 있고, 무엇을 보고 있으며, 얼마나 빨리 움직이고 있는지 말해주고 있다. 데이터는 실시간으로 수집, 표현되며, 행동하고 있다. 데이터 참가자들의 규모는 그 크기 등급대로 증가되고 있다.
더 많은 사용자들과 센서들이 더 많은 애플리케이션과 플랫폼에 주입되면서, 개발자들은 중대한 실세계 문제들을 다룰 수 있게 되었다. 그 결과로, 웹 기회는 더 이상 산술급수적이 아닌, 기하급수적으로 증가하고 있다. 이런 이유로, 올해의 주제를 웹 스퀘어드로 정했다. 1900-2004년에 성냥에 불을 붙였다면, 2005-2009년은 불이 도화선으로 옮겨갔고 2010 은 폭발하게 될 것이다.
우리가 최초로 "웹 2.0"이란 용어를 소개한 이후로, 사람들은 그 다음은 무엇인지 질문하고 있다. 웹 2.0 이 일종의 소프트웨어 버전(닷컴 붕괴 후, 웹의 재림에 관한 논쟁보다는)을 의미했다는 가정하에 우리는 끊임없이 "웹 3.0"에 대해 질문을 받고 있다. 시만틱 웹인가요? 소셜 웹인가요? 모바일 웹인가요? 아니면 일종의 가상현실을 말하는 것인가요?
웹은 이 모든 것이며 그 이상을 의미한다.
웹은 더 이상 세상에 있는 무엇인가를 묘사하는 정적인 HTML 페이지들의 집합체가 아니다. 웹은 점차적으로 세상 그 자체가 되어가고 있다. 즉, 세상에 있는 모든 사람들과 사물들이 지능적으로 수집되고 처리되는 데이터의 아우라(aura)인 "정보 그림자(Information shadow)" 를 발산하고 있는데, 이는 놀랄 만한 기회와 정신을 어지럽힐 정도의 암시성을 제공하고 있다. 웹 스퀘어드는 바로 이러한 현상을 탐구하는 방식이다.
집단지성의 재정의: 새로운 감각 입력
웹이 어디로 가는지 이해하기 위해 웹 2.0에 근간에 있는 기본적인 아이디어 중 하나인, 이른바 성공적인 네트워크 애플리케이션들이란 집단지성을 이용하기 위한 시스템이다 라는 내용을 다시 살펴보자.
현재 많은 사람들이 "크라우드소싱"의 관점에서 이 아이디어를 이해하고 있다. 크라우드소싱이란 대규모 그룹의 사람들이 개별 참가자들에 의해 제공되는 것을 훨씬 넘어서는 가치를 지닌 집단적 작업을 창조할 수 있다는 개념이다. 전체적으로 보면 웹은 크라우드소싱의 놀랄만한 산물이다. 웹은 이베이, 크레이그리스트에서는 시장이 되었고, 유튜브와 플리커에서는 혼합된 미디어 컬렉션, 그리고 트위터, 마이스페이스 그리고 페이스북에서는 거대한 개인적인 삶의 흐름의 집합체가 되었다.
또한 많은 사람들이, 애플리케이션은 특정한 업무를 수행하도록 사용자들을 인도하는 방식으로 구축될 수 있다고 이해하고 있다. 온라인 백과사전(위키피디아)의 구축, 온라인 카탈로그에 대한 논평(아마존), 지도상에 데이터 포인트를 추가하는 작업(많은 웹 지도 애플리케이션), 혹은 가장 인기 있는 뉴스를 찾아내는 작업(디그, 트와인)등은 바로 이러한 전형적인 예라 할 수 있다. 아마존의 메카니컬 터크(Mechanical Turk)는 컴퓨터 만으로는 수행하기 어려운 업무를 사람들이 처리하도록 하기 위한 보편화된 플랫폼을 제공하는 형태로 지금까지 발전해 왔다.
그런데 이러한 것들이 정말 우리가 말하는 집단지성을 뜻하는 것일까? 과연 지성의 정의가 주변 환경과 반응하며 학습해 나가는 유기체의 특성이라는 것 하나만 존재하는 것일까? (지금 당장은, 자가인식에 대한 문제는 완전히 논외로 두고 있음을 염두에 두자.)
웹(단지 월드 와이드 웹으로서 공식적으로 알려진 PC 기반의 애플리케이션이 아닌, 연결된 모든 장치와 애플리케이션의 네트워크로서 광범위하게 정의되는 웹)을 신생아라고 생각해 보자. 신생아는 볼 수는 있지만, 인지할 수 없다. 느낄 수는 있지만, 입을 대기 전까지는 그것이 무엇인지 알지 못한다. 미소 짓는 부모가 하는 말을 들을 수는 있겠지만, 이해할 수는 없다. 신생아는 감각이라는 바다에 빠져 있지만, 이해할 수 있는 것은 거의 없으며 주변 환경을 제어하지 못한다.
점차적으로, 세계는 이성적이 되어가고 있다. 신생아는 자신이 흡수하는 여러 감각들을 조정하고, 소음으로부터 신호를 걸러내며, 새로운 기술을 배우고, 한 때는 힘들어했던 일들을 자동화하듯 쉽게 해결하게 된다.
이 시점에서 이런 질문을 해보자. 과연 웹은 성장해 가면서 똑똑해질까?
현재 웹에서 국제공용어로 통하고 있는 검색에 대해 생각해보자. 브라이언 핑커톤(Brian Pinkerton)의 웹크롤러(webcrawler)로 시작된 최초의 검색 엔진은, 말하자면 닥치는 대로 모든 것을 물고 늘어지는 식이었다. 게걸스럽게 링크의 뒤를 따라가, 발견한 모든 것을 먹어 치웠다. 키워드와 일치하는 모든 내용을 일일이 하나씩 비교해가며 순위를 정했다.
1998년, 래리 페이지(Larry Page)와 세르게이 브린(Sergey Brin)은 한 가지 돌파구를 찾아냈다. 즉, 링크는 단순히 새로운 콘텐츠를 찾아내는 수단이 아니라, 좀 더 세밀한 자연어 문법과 연결해서 그 순위를 정하는 수단이라는 점을 깨달은 것이다. 본질적으로, 모든 링크는 하나의 득표수가 되어가고 있고, 일반 사람들보다는 지식을 가진 사람들로부터의 득표수(순서대로 투표하는 사람들의 질과 수에 의해 측정되는)가 더 중요해지고 있다.
현대의 검색 엔진들은 검색 결과를 산출하기 위해 수 백 가지의 순위선정 기준과 복잡한 알고리즘을 사용하고 있다. 데이터 소스들 중 단연 돋보이는 것은 검색 용어의 빈도수와 검색 결과에 대한 사용자들의 클릭 수 그리고 개인별 맞춤 검색과 브라우징 기록에 의해 생성되는 피드백 루프이다. 예를 들어, 다수의 사용자들이 특정 검색 결과 페이지 상의 첫 번째 항목보다 다섯 번째 항목을 클릭하기 시작했다면, 구글의 알고리즘은 이를 다섯 번째 것이 첫 번째 것보다 더 낫다는 신호로 받아들여 최종적으로 검색 결과를 조정한다.
이제 좀 더 현대적인 검색 애플리케이션인 아이폰을 위한 구글 모바일 App를 고려해보자. 이 애플리케이션은 전화기를 귀로 가져가는 움직임을 탐지해 자동으로 음성 인식 모드로 전환한다. 아이폰은 목소리를 듣기 위해 마이크로폰을 사용하고, 음성 인식 데이터베이스와 알고리즘 뿐만 아니라, 검색 데이터베이스에서 가장 빈번하게 검색되는 용어와의 연관성을 참조해서 말하고 있는 내용을 해독한다. 또한 GPS나 송신탑의 삼각측량법을 이용해서 현 위치를 탐색한다. "피자"란 단어를 검색할 경우, 여러분이 원하는 검색 결과는 현 위치에서 가장 가까운 피자 식당의 이름, 위치 그리고 연락처 정보일 것이다.

뜻하지 않게, 우리는 키보드와 형식적인 문법을 사용해서 검색을 하는 것이 아니라, 웹과 대화를 하게 되었다. 명시적으로 말할 필요 없이 웹은 뭔가(가령 현재 위치 같은)를 이해하기 충분할 만큼 똑똑해지고 있으며, 이것은 단지 시작일 뿐이다.
그리고 GPS 좌표와 주소를 매핑하는 것처럼, 애플리케이션이 참조하는 일부 데이터베이스는 애플리케이션을 "가르치고" 있다. 반면, 음성 인식과 같은 다른 애플리케이션들은 크라우드소싱으로 만들어진 대규모로 처리되는 데이터 집합에 의해 "학습"을 한다.
분명한 점은, 이런 것들이 우리가 몇 년 전에 보았던 것 이상으로 "똑똑한" 시스템이라는 사실이다. 음성인식과 검색, 검색결과와 위치를 조율하는 것은, 신생아가 조금씩 주변의 사물을 인식하는 것과 흡사하다. 웹은 계속 성장하고 있으며, 우리 모두가 웹의 집단적인 부모가 되어가고 있다.
웹의 학습 방식: 명시적 vs. 함축적 의미
웹은 어떤 식으로 학습을 할까? 일부 사람들은 컴퓨터 프로그램들이 의미를 이해하고 반응하는 것을 상상하고 있는데, 이러한 의미는 일부 특별한 분류방식으로 암호화될 필요가 있다. 하지만 실제로 우리 눈앞에 있는 것은 데이터 본체로부터 "추리"에 의해 학습되는 의미이다.
음성 인식과 컴퓨터 비젼은 모두 이러한 종류의 기계 학습의 훌륭한 예라 할 수 있다. 하지만, 중요한 점은 기계 학습 기술은 센서 데이터를 훨씬 뛰어 넘는 곳에까지 적용된다는 사실이다. 예를 들어, 구글의 광고 옥션은 학습 시스템이며, 기계 학습 알고리즘에 의해 실시간으로 최적의 광고 위치와 가격이 만들어진다.
또 다른 경우, 의미는 컴퓨터를 "가르치기"도 한다. 즉, 애플리케이션에 하나의 구조화된 데이터 셋과 다른 데이터 셋 사이의 매핑이 주어진다. 예를 들어, 거리의 주소와 GPS 좌표간의 제휴는 학습된다기 보다는 가르치는 것에 더 가깝다. 두 데이터 셋 모두 구조화됐지만, 이들을 연결하기 위해서는 통로가 필요하다.
또한 두 데이터 셋 간의 연결을 인지하는 방법을 애플리케이션에게 가르침으로써 구조화되지 않은 데이터에 구조성을 부여하는 것도 가능하다. 예를 들어, 아이폰 애플리케이션인 You R Here는 이러한 두 가지 접근법을 교묘히 결합하고 있다. 아이폰 카메라를 사용해서 공원의 입구에 있는 안내도나 다른 자전거 주행도 같은, 구글맵과 같은 일반적인 매핑 애플리케이션에는 없는 세부정보를 담은 지도의 사진을 찍는다. 그리고 아이폰의 GPS를 사용해 지도상에서 현재 위치를 설정한 뒤, 한참 걸어간 후에 멈춰서 두 번째 지점을 설정한다. 그리고 나면 구글맵에서 처럼, 아이폰을 이용해서 사용자 정의 지도의 이미지상에서 자신의 위치를 쉽게 추적할 수 있다.
웹에서 가장 근본적이며 유용한 서비스 중 일부는, 일단 인지를 하고 나서 처음에는 구조화되지 않은 것처럼 보이는 데이터에서 미처 보지 못한 규칙을 가르치는 방식으로 만들어져 왔다.
타이 칸(Ti Kan), 스티브 쉬러프(Steve Scherf), 그리고 CDDB의 창시자 그레이엄 톨(Graham Toal)은 CD의 트랙 정보가 가수, 앨범, 그리고 노래제목과 상관관계를 맺을 수 있는 유일한 서명을 형성한다는 점을 깨달았다. 래리 페이지와 세르게이 브린은 링크가 득표수라는 점을 깨달았다. Wesabe의 마크 헤드런드(Marc Hedlund)는 모든 신용카드 결재 또한 득표수이며, 거기에는 동일한 가맹점을 반복적으로 방문한다는 의미가 숨어 있음을 깨달았다. 페이스북의 마크 주커버그(Mark Zuckerberg)는 온라인상의 친구관계는 실제로 일반화된 소셜 그래프(Social Graph)를 구성한다는 점을 깨달았다. 이것 들은 처음에는 구조화되지 않은 것처럼 보이던 데이터를 인간과 기계 모두를 사용해서 구조화된 데이터로 변모시키고 있다.
핵심 사항: 웹 2.0시대의 핵심 역량은 함축된 메타데이터를 찾아내어 이를 둘러싸고 있는 생태계를 육성하는 메타데이터를 잡아내기 위한 데이터베이스를 구축하는 것이다.
웹과 현실 세계의 조우: "정보 그림자(Information Shadow)"와 사물의 인터넷(Internet of Things)
"센서 기반 애플리케이션"이라고 하면, 많은 사람들은 RFID 태그나 ZigBee 모듈로 구동되는 애플리케이션의 세계를 떠올릴 것이다. 하지만 이러한 미래는 그리 가까이 있지 않으며, 배포 테스트나 소수의 초기 단계 애플리케이션에서만 현존하고 있다. 그런데 많은 사람이 놓치고 있는 점이 하나 있는데, 바로 센서 혁명이 이미 얼마나 진행됐느냐는 점이다. 센서 혁명은 모바일 시장의 감춰진 얼굴이자 가장 폭발적인 기회라 할 수 있다.
오늘날의 스마트폰에는 마이크로폰, 카메라, 동작 센서, 근접 센서, 위치 센서(GPS, 송신탑의 삼각측량, 심지어는 나침반까지)가 내장되어 있다. 이러한 센서들은 독립형 애플리케이션의 사용자 인터페이스에 혁명을 가져왔다. 이의 전형적인 예가 바로 불기만 하면 되는 아이폰용 오카리나(Smule"s Ocarina)이다. 하지만 모바일 애플리케이션들은 연결된 애플리캐이션 이라는 점을 잊지 말아야 한다. 웹 2.0의 근본적인 교훈은 웹이나 이동전화기반의 그 어떠한 네트워크 애플리케이션에도 적용된다는 점이다. 센서기반 애플리케이션들은 더 많은 사람들이 사용하고, 좀 더 많은 사용법을 창조해내는 피드백 루프를 생성하는 데이터를 수집하면서 개선되도록 설계될 수 있다. 구글 모바일 App에 있는 음성 인식은 이러한 애플리케이션 중 하나이다. 인터넷에 연결된 새로운 GPS 애플리케이션들 또한 피드백 루프가 내장되어 있어서, 현재 속도를 보고하고 이 정보를 사용해서 전방의 교통정보에 근거해 도착 시간을 추정한다. 오늘날, 교통 패턴은 대략적인 추정되고 있는데, 앞으로는 실시간으로 측정될 것이다.
망(Net)은 생각 이상으로 빠른 속도로 똑똑해지고 있다. 사진에 붙는 지오태깅(geotagging)을 고려해보자. 초기에는 사용자들이 태그를 부착해서 사진과 위치정보 간의 관계를 컴퓨터에게 알려줬다. 모든 사진에 지오태그가 부착되는 그 날, 카메라들은 그 위치를 알게 될 것이며, 인간이 제공한 그 어떤 것보다 훨씬 더 정확한 위치를 알게 될 것이다.
그리고 하나의 데이터 셋에서 정확도가 커질수록 다른 데이터 셋의 정확도도 높아진다. 지오태그가 부착된 플리커 사진에 의해 생성된 아래 지도가 얼마나 정확한지 살펴보자. 수 억장의 사진이 제공된다면 이 지도는 얼마나 더 정확해질까?
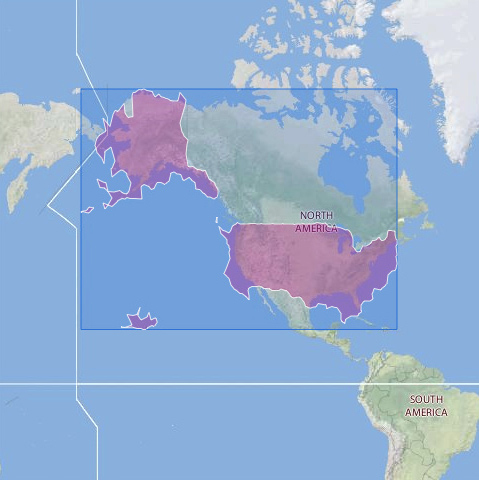
미국의 플리커 지오태그 지도
http://flickr.com/photos/straup/2972130238/
망의 시각센서 네트워크를 위한 보조도구들은 위치에 제한받지 않을 것이다.
이것들은 초기 상태로 남아있지만, 애플 iPhoto "09의 안면인식은 꽤 훌륭하다. 과연 인식하지 않은 사람들만 보여줄 수 있는 시스템의 출현을 위해 이름을 부착한 얼굴이 충분해지는 시점은 언제가 될까? (애플이 시스템 서비스로 이러한 데이터를 제공할지 여부는 여전히 의문으로 남아있다. 또한 다른 누군가가 네트워크 서비스로 제공할지 여부도 확실치 않다.)
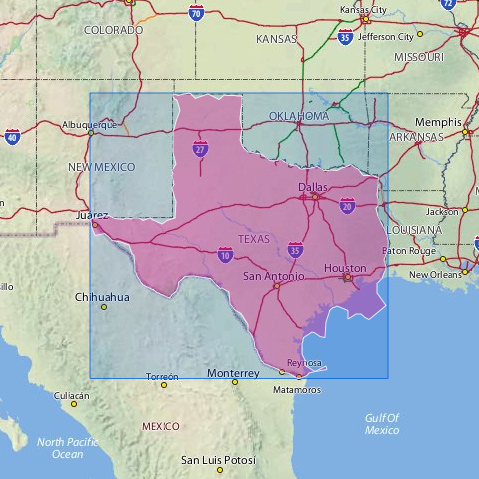
텍사스의 플리커 지오태그 지도
http://flickr.com/photos/straup/2971287541/
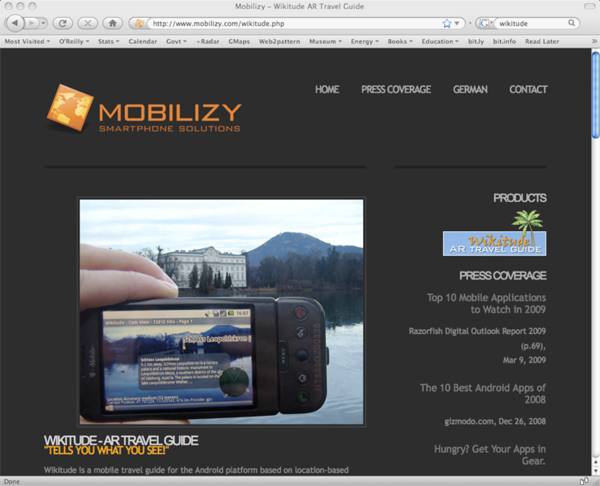
안드로이드를 위한 위키튜드(Wikitude) 여행 가이드 애플리케이션은 훨씬 더 향상된 이미지 인식을 한다. 이 애플리케이션은 이동전화 카메라로 기념물이나 다른 흥미로운 장소를 찍은 지점을 자신의 온라인 데이터베이스에서 찾는다. 화면에는 카메라가 찍은 것은 물론, 현재 여러분이 보고 있는 것에 대한 추가 정보까지 표시된다. 즉, 헤드업 디스플레이 기능이 실현되고 있는 것이다. 이 애플리케이션은 미래의 "증강현실(augmented reality)"의 첫 발을 내딛고 있는데, 여러분이 현재 보고 있는 장소를 추적하기 위해 나침반을 사용하면서, 관심 있는 지점까지의 거리를 겹치는 방식을 사용한다. 이 이동전화를 사용해서 관심 있는 지점 근처의 지역을 한 바퀴 둘러볼 수도 있다.
Layer는 이러한 아이디어를 더욱 발전시켜, 이동전화 카메라를 통해 본 "증강현실" 콘텐츠의 다중 레이어를 위한 프레임워크를 약속하고 있다.
센서기반의 애플리케이션이 초능력을 준다고 생각해보자. 다크슬라이드(Darkslide)는 슈퍼맨 같은 시력을 선사해서 여러분 근처에 있는 사진을 보여주고 있다. 아이폰 트위터 애플리케이션은 "근처에 있는 최근의 트윗을 찾아" 초강력 청력을 부여해서 주변에서 진행되고 있는 대화를 고를 수 있게 한다.
이 모든 해결책들은 ThingM의 마이크 쿠니아브스키(Mike Kuniavsky)가 언급했던 사실을 반영하고 있다. 그는 실 세계의 사물들은 사이버공간에서 "정보 그림자"를 갖고 있다고 주장했다. 예를 들어, 책은 아마존, 구글 북서치, 굿리드(Goodreads), 쉘파리(Shelfari) 그리고 라이브러리씽(LibraryThing), 이베이, 북무우취(BookMooch), 트위터, 그리고 수 천개의 블로그 상에서 정보 그림자를 갖고 있다.
노래는 아이튠, 아마존, 랩소디(Rhapsody), 마이스페이스, 페이스북에서 정보 그림자를 가지고 있다. 한 개인의 경우 수 많은 이메일, 인스턴스 메시지, 전화통화, 트윗, 블로그 포스팅, 사진, 비디오 그리고 정부 문서에서까지 정보 그림자를 가지고 있다. 슈퍼마켓 선반에 놓인 상품, 딜러의 차고에 있는 자동차, 하역장에 있는 새로 채굴된 붕소, 작은 마을의 대로변에 있는 상점 등 모든 것은 현재 정보 그림자를 갖고 있다.
대부분의 경우, 이러한 정보 그림자들은 ISBN이나 ASIN, 부품번호 혹은 주민번호, 자동차 번호 등과 같은 유일한 식별자에 의해 실 세계에 있는 사물이나 사람들과 긴밀히 연결되어 있다. 다른 형태의 식별자도 존재한다. 이름에 주소나 전화번호를 결합하거나, 이름과 사진을 결합한 것 그리고 아주 확실한 알리바이 조차도 처참하게 무너뜨릴 수 있는 특정 지역으로부터 걸려온 전화와 같은 것들도 유일성을 나타낼 수 있다.
"사물의 인터넷"에 관해 말하는 많은 사람들은 일상생활에서 사용되는 물체에 IP 주소와 슈퍼 RFID 칩이 결합될 것이라고 가정하고 있다. 즉, 사물의 인터넷을 구현하기 위해서는 모든 물체가 유일한 식별자를 가져야만 한다고 가정하고 있다.
웹 2.0 감성이 우리에게 말하고 있는 것은 다양한 종류의 센서 데이터의 기여에 의해 사물의 인터넷에 도달할 것이며, 기계 학습 애플리케이션들은 자신에게 유입된 데이터를 점점 더 확실히 이해하게 될 것이라는 점이다. 사물의 인터넷이라는 흐름에 합류하기 위해 슈퍼마켓 선반에 있는 한 병의 와인에까지 RFID칩을 붙일 필요는 없다. 상표를 찍은 사진만으로도 충분하다. 나머지는 이동전화, 이미지 인식, 검색 그리고 감각적인 웹이 맡게 될 것이다. 즉, 슈퍼마켓에 있는 각 상품에 기계가 인식할 수 있는 유일한 ID가 부착될 때까지 기다리지 않아도 된다. 대신, 바코드, 사진태그 그리고 부르트포싱(brute0forcing) 같은 간단한 해킹기술을 응용해서 식별할 수 있다.
제프 조나스(Jeff Jonas)는 신원 확인 작업을 하면서 아주 흥미진진한 사실을 언급했다. 조나스의 작업 중 일부는 다양한 소스들로부터 유명한 미국 사람들에 대한 데이터베이스를 구축하는 것이었다. 시스템이 모든 변동사항을 식별할 만큼 충분한 정보를 보유하기 전에, 그의 데이터베이스에는 이미 6억3천만 건 정도의 "신원"을 확보하고 있었다. 그런데 특정한 순간에 데이터베이스가 학습을 시작하면서 용량이 줄어들기 시작했다. 신규로 데이터가 들어감에 따라 데이터베이스는 커지기는 커녕, 더 작아졌다. 6억 3천만에 3천만 건이 더해져서 6 억 건의 데이터가 만들어졌는데, "컨텍스트 누적(context accumulation)" 이라는 인지 계산법에 의해서 이런 마술과 같은 일이 일어난 것이다.
정보 그림자가 두터워짐에 따라, 좀 더 견고하고, 명시적인 메타데이터에 대한 요구는 감소되고 있다. 카메라와 마이크로폰은 웹의 눈과 귀가 되고 있고, 모니터 센서, 근접센서, GPS는 위치인식은 감각기관이 되어가고 있다. 정말, 웹이라는 신생아는 계속 자라고 있다. 우리는 인터넷과 만나고 있으며, 우리가 바로 인터넷이다.
센서와 모니터링 프로그램들은 단독적이 아닌, 자신들의 인간 파트너와 한 조를 이루며 동작한다. 우리는 중요하다고 생각되는 얼굴을 인식하도록 사진 프로그램을 가르치고, 관심 있는 뉴스를 공유하며, 트윗에 태그를 덧붙여 좀 더 쉽게 분류해서 정리할 수 있다. 우리 자신을 위해 가치를 추가하면서, 소셜 웹에도 역시 가치를 추가하고 있다. 디바이스들이 우리의 활동영역을 넓히고 있고, 우리 역시 디바이스의 영역을 확장하고 있다.
이러한 현상은 소비자 웹에만 국한되지 않는다. IBM의 스마터 플라넷 이니셔티브와 나사(NASA)와 시스코의 "planetary skin" 프로젝트는 비즈니스가 센서 웹에 의해 얼마나 심도있게 변형될 것인지를 보여주고 있다. 정유회사, 제철회사, 공장 그리고 공급망 들은 웹 애플리케이션에서 볼 수 있는 것과 정확히 동일한 종류의 기계 학습 알고리즘과 센서로 무장하고 있다.
뻔하디 뻔한 대기업들의 선언에서는 미래가 명확히 보이고 있지 않지만, 초기 수용자들과 "알파 긱스(alpha geeks)"의 솜씨 좋은 최적화에서는 명확히 보이고 있다. 레이다 블로거인 넷 토킹턴(Nat Torkington)은 웰링턴에서 만났던 택시기사 이야기를 해주고 있는데, 이 택시기사는 6주 동안에 태운 손님들의 기록(GPS, 날씨, 승객 그리고 다른 세가지 변수)을 컴퓨터에 저장해서, 하루 중 손님이 제일 많은 특정 시간을 알아내기 위해 몇 가지 분석을 했다고 한다. 이 분석 결과를 이용해서 그는 다른 택시기사에 비해 적게 일하고도 높은 수익을 거둬들일 수 있었다고 한다. 세상을 도구화하는 것은 충분히 그럴만한 가치가 있다.
데이터에 있는 패턴을 보기 위한 데이터 분석, 시각화 그리고 다른 기술들은 점점 더 가치 있는 기술 집합체가 되어가고 있다.
이는 물체 특히 잘 알려진 집합체(책이나 뮤직 컬렉션 같은)의 인스턴스들인, 대체품에 대한 유일한 식별자로서의 역할을 말하는 것이 아니다. 하지만 디지털 데이터에 선험적 의미를 추가하기 위한 공식적인 시스템들이, 실제로는 특성 인식을 통해 의미를 추출하는 비공식적 시스템보다 강력하지 않다는 점을 보여주는 증거가 존재한다. ISBN은 책에 대한 유일한 식별자를 제공하지만, 오히려 제목 + 저자가 피부에 더 와 닿을 것이다.
원시 센서 데이터를 체계적으로 분류하는 프로젝트들은 아마도 Astrometry 프로젝트의 노선을 따라 만들어질 것이다. 이 프로젝트의 창시자는 "우리는 과거와 미래, 그리고 현재까지 수집된 모든 유용한 천문학 이미지들을 위한 정확하고, 표준에 맞는 천문학 메타 데이터를 생성하기 위한 "천체 측정학 엔진"을 구축하고 있다"라고 주장하고 있다. 이 엔진을 사용해서 Flickr astrotagger bot은 천체의 이미지를 플리커에서 찾아 적절한 메타데이터를 제공해서, 이름으로 천문 이미지들을 검색할 수 있게 한다. 이는 산만한 센서 데이터를 정규화된 검색 데이터베이스와 매핑하는 검색 서비스인 CDDB와 유사한 서비스이다.
이러한 것들은 초기의 열성가들에 의해 만들어졌다. 그들은 기업가들이 동일한 원칙을 새로운 비즈니스 기회에 적용하는 세계가 올 것을 예고했다. 우리가 살고 있는 세계에서 센서가 점점 더 활성화됨에 따라, 그들의 데이터 흐름으로부터 의미와 가치가 얼마만큼 추출될 수 있는지에 대한 놀랄만한 계시가 나올 것이다.
이른바 "스마트 전기 그리드"를 생각해보자. 에너지 관련 센서 데이터를 위한 중성 백엔드 웹서비스인 AMEE의 창시자인 가빈 스타크(Gavin Stark)는 연구자들이 영국의 1200만 가구로부터 수집한 스마트 메타 데이터를 결합하면서, 각 가정에 있는 가전제품들이 유일한 에너지 서명(signature)를 가지고 있는 사실을 발견했다는 점에 주목했다. 이 에너지 서명을 이용해서 각 가전제품이 사용한 전력량 뿐만 아니라, 각각의 주요 가전제품의 모델과 제조사를 결정하는 것이 가능하다. CDDB를 소비자 가전제품으로 생각하라.
구조화되지 않은 데이터와 구조화된 데이터 셋과의 매핑은 핵심적인 웹 스퀘어드 역량이 될 것이다.
실시간의 도래: 집단 사고방식(Collective Mind)
좀 더 대화형이 되어감에 따라 검색은 더 빨라졌다. 매일 혹은 심지어 매 시간마다 검색이 필요한 수 천 만개의 사이트에 블로그들이 추가되었으나, 마이크로블로깅은 실 시간적인 갱신을 요구하고 있다. 이는 인프라와 접근법 모두에 있어 중대한 변화가 이루어지고 있음을 의미한다. 트위터에서 현재 유행하는 주제에 대해 검색을 하면, 지금 당장 무슨 일이 일어나고 있는지 보세요" 그리고 뒤이어 "검색을 시작한 이후로 42개의 결과가 더 검색되었습니다. 이 내용을 보려면 다시 검색하세요." 라는 메시지를 보게 될 것이다:
더군다나, 사용자들 역시 검색 시스템과 함께 계속 진화하고 있다. 트위터에서, 공유된 사건에 대한 실시간 검색을 활성화하는 사용자들 간의 약속인 해쉬태그를 붙여보자. 다시 한번, 여러분은 사람들의 참여가 어떤 식으로 원시 데이터 스트림을 구조적으로 만드는지 보게 될 것이다.
실시간 검색은 실시간 응답을 이끌어낸다. 재 트윗된 "정보 캐스케이드(Information Cascades)"들은 트위터에서 순식간에 긴급속보 형태로 퍼져나가서, 무슨 일이 발생했는지 알고자 하는 많은 사람들을 위한 원천 소스가 되고 있다. 그리고 이것 역시 단지 시작일 뿐이다. 트위터와 페이스북의 status update 같은 서비스를 통해 웹에 새로운 데이터 소스가 추가되고 있으며, 이것들은 우리의 집단적 사고방식 상에서 실시간 지표가 되어가고 있다.
최근에 트위터에 의해 정치적 시위들이 발생하고 조정된 적이 있는 과테말라와 이란은 트위터의 영향력을 몸소 체험했다.
이러한 사실은 다음과 같은 시기 적절한 논쟁을 불러 일으키고 있다. 많은 사람들이 기술의 탈인간화 효과에 대해 걱정하고 있고, 우리 역시 같은 고민을 갖고 있다. 하지만 다른 측면에서 보면, 기술은 소통의 통로를 넓게 열어 공유된 컨텍스트를 제공하고, 궁극적으로는 정체성까지 공유하도록 이끌고 있다.
트위터는 또한 애플리케이션들이 어떻게 장치에 적응하는가에 대한 중요한 사실을 가르쳐주고 있다. 트윗은 140 글자로 제한된다; 트위터의 이러한 제한은 봇물처럼 넘쳐 흐르는 혁신을 이끌어냈다. 즉, 트위터 사용자들은 속기법(@username, #hashtag, $stockticker)을 개발했으며, 트위터 클라이언트들은 곧 클릭 가능한 링크로 변모했다. 전통적인 웹 링크에 대한 URL 속기법이 유명해졌고, 곧 클릭된 링크에 대한 데이터베이스가 새로운 실시간 분석을 가능하게 한다는 사실을 깨닫게 해주었다. 예를 들어, Bit.ly는 실시간으로 생성해낸 링크에 대한 클릭 수를 보여주고 있다.
이러한 결과로, 검색, 분석 그리고 소셜 네트워크로 대표되는 웹 서비스의 경쟁상대로 부상하고 있는 트위터 주변에 새로운 정보 계층이 구축되고 있다. 트위터는 또한 여러분이 API를 제공할 때 발생할 수 있는 것들에 대해 모바일 서비스 공급자들에게 객체 학습을 제공하고 있다. 트위터 애플리케이션 생태계로부터의 학습은 SMS와 다른 모바일 서비스, 혹은 이들을 대체하면서 성장할 수 있는 서비스를 위한 기회를 보여주고 있다.
실시간은 미디어나 모바일에 국한되지 않는다. 구글이 링크가 하나의 득표수라는 사실을 깨달았듯이, 월마트는 고객의 상품 구매도 하나의 득표수이며, 금전등록기는 이러한 득표수를 세는 센서라는 사실을 알아차렸다. 실시간 피드백 루프가 상품 목록을 관리하고 있는 것이다. 월마트를 웹 2.0 회사라고는 할 수는 없겠지만, 틀림없는 웹 스퀘어드 회사라고 할 수 있다. 이들의 사업운영에는 IT가 접목되어 있어, 고객들의 데이터에 의해 구동되고 있는데, 이로 인해 엄청난 경쟁우위를 갖게 된다. 웹 스퀘어드 기회의 대단한 점 중 하나는, 독점적인 공급망 없이도 이러한 종류의 실시간 지능을 작은 소매업자들에게 제공할 수 있다는 점이다.
말콤 글래드웰(Malcolm Gladwell)은 자신의 뉴요커 기고문에서 Tibco의 CEO이자 창업자인 바이벡 래너다이브(Vivek Ranadive)의 다음과 같은 감동적인 설명을 인용했다:
"이 세상에 있는 모든 것들은 이제 실시간화 되고 있다. 따라서 중국에서 만들어진 특정 종류의 신발이 근처에 있는 작은 상점에 진열되기까지 6개월을 기다릴 필요가 없다. 소프트웨어 덕분에 모든 것이 순식간에 일어난다"
굳이 센서에 의해 구매가 발생하지 않더라도, 실시간 정보는 비즈니스에 큰 영향을 주고 있다. 고객들이 자신들의 목적을 행동이나 말을 통해 웹에(그리고 트위터에) 게시하면, 회사들은 이를 듣고 대화에 참여해야만 한다. 컴캐스트(Comcast)라는 회사는 트위터를 이용해서 고객 서비스 접근법을 바꾸고 있으며, 다른 회사들 역시 이에 동조하고 있다.
실시간 피드백 루프에 대해 최근에 들었던 또 다른 놀라운 이야기는, 오바마 선거캠프에서 사용했던 후디니(Houdini) 시스템이다. 이 시스템은 유권자들이 실제로 투표를 하자마자 투표독려예상 목록에서 해당 투표자를 제거한다. 중요 지역에 있는 투표 감시자들은 투표자 리스트에서 줄이 그어진 이름들을 보고한다. 그리고 나서 보고된 사람들은 투표독려예상 목록에서 "사라지게"된다. (순식간에 명단이 사라지므로 이 시스템을 후디니 라고 지었다고 한다.)
후디니는 아마존의 메카니컬 터크(Mechanical Turk)에서 확실히 드러나고 있다. 센서 역할을 하는 한 그룹의 지원자들과 다중 실시간 데이터 큐는 동기화되며, 동일한 시스템에서 작동기로 사용되고 있는 다른 그룹의 지원자들을 위한 지침에 영향을 주는데 사용된다.
비즈니스는 자원할당, 고객서비스, 제품 개발을 위한 훨씬 더 효율적인 피드백 루프를 알려주는 핵심 신호로써 실시간 데이터를 이용하는 법을 배워야 한다.
결론: 문제의 본질
지금까지 언급한 내용은 여러 가지 방식으로 웹 스퀘어드 시대의 기회에서 가장 중요한 부분이 무엇이 될 것인가에 대한 하나의 서론을 얘기한 것이다.
웹을 위한 새로운 방향은, 물리적 세계와의 충돌의 과정으로, 비즈니스를 위해 엄청난 새로운 기회와 전 세계에서 가장 긴급한 문제들과의 차별성을 두기 위한 거대한 새로운 가능성을 열고 있다.
이미 이런 현상에 대한 수 백 가지의 예가 존재하고 있다(아래의 사례접수 참조). 하지만 에너지 생태계에서부터 보건의료에 대한 접근까지, 훨씬 더 큰 진전을 이뤄야 할 필요가 있는 영역이 매우 많다. 혼란에 휩싸인 작금의 금융 시스템은 말할 것도 없다. 심지어는 친규제적 환경에서도, 실시간으로 자동화된 금융 시스템이 정부의 규제 감독관들을 제쳐버렸다. 과연 우리가 소비자 인터넷으로부터 배웠던 것이 새로운 21세기 금융 규제 시스템을 위한 기초로 제 역할을 할 수 있을까? 이렇게 되기 위해서는 학습 기계, 변칙사항들을 탐지할 수 있는 알고리즘, 인원부족으로 인해 과로에 지친 규제 감독관들이 아닌, 진정으로 미래를 걱정하는 사람들의 감시가 이루어지는 투명성이 필요하다.
웹 2.0 이벤트를 시작했을 때, 우리는 "웹은 플랫폼이다"라고 단언했다. 그 이후로, 수 천 개의 비즈니스와 수 백만의 사람들이 웹이라는 플랫폼 위에 구축된 서비스와 제품들에 의해 변화되어왔다. 하지만 2009년은 웹의 역사에서 변곡점을 찍고 있다. 이제 우리가 구축했던 플랫폼의 진정한 힘을 이용할 때가 되었다. 웹은 더 이상 산업 자체가 아닌, 세상 그 자체가 되었다.
그리고 세상은 우리의 도움이 필요로 하고 있다.
세상에서 가장 급박한 문제를 해결하려고 한다면, 우리는 기술, 비즈니스 모델, 그리고 아마도 가장 중요한 항목인 개방성의 철학, 집단 지성 그리고 투명성으로 대표되는 웹의 진정한 힘이 작용하도록 만들어야 한다. 이렇게 하기 위해서, 우리는 웹을 한 단계 더 끌어올려야 한다. 이제 더 이상 점진적인 진화를 할 여유가 없다.
웹이 실 세계를 독려할 때가 왔다. 웹이 세상과 만나는, 바로 이것이 바로 웹 스퀘어드이다.
5년 전, 우리는 간단한 아이디어를 근거로 컨퍼런스를 개최했었고, 이제 그 아이디어는 하나의 운동으로 발전했다. 애초에 웹 2.0 컨퍼런스(현재는 웹 2.0 서밋)는 닷컴 붕괴 후 길을 잃고 헤매던 산업계에 자신감을 회복시켜 주기 위한 목적으로 기획되었다. 이전에 주장했듯이, 웹은 완성된 것이 아니며, 컴퓨터 애플리케이션과 서비스로 대표되는 문화변혁 세대를 위한 강력한 플랫폼으로 거듭나고 있는 중이다.
첫 번째 프로그램에서, 우리는 닷컴 붕괴 후 매우 처참하게 실패한 기업이 있었던 반면, 일부 기업들은 어떻게 살아남게 되었는지에 대한 질문을 받았다. 또한 신생성장 기업들에 대한 연구를 진행하면서, 그들이 그렇게 빨리 성장하는 이유에 대해서도 질문을 받았다. 그리고 이러한 질문에 대한 답을 구하는 과정은 새로운 플랫폼 상에서의 비즈니스 규칙을 이해하는데 도움이 되었다. 우리의 통찰력 중 으뜸은 "플랫폼으로서의 네트워크"인데, 이는 단순히 네트워크를 경유하여 예전의 애플리케이션을 제공하는 것("서비스로서의 소프트웨어") 이상을 의미한다. 즉, 문자 그대로 더 많은 사람들이 사용할 수 있도록 개선하고, 사용자들을 더 확보할 뿐만 아니라 사용자들의 기여를 통해 만들어지고 그들로부터 배우는 네트워크 효과를 이용하는 애플리케이션을 구축하는 것을 의미한다.
구글과 아마존에서 위키피디아, 이베이 그리고 크레이그리스트(craigslist)까지, 우리는 소프트웨어에 의해 실현되었지만, 밀접하게 연결된 사용자 커뮤니티와의 협력을 통해 창조된 가치를 목격했다. 그 이후로, 유튜브, 페이스북 그리고 트위터와 같은 강력해진 새로운 플랫폼들이 새로운 방식으로 동일한 통찰력을 여실히 보여줬다. 웹 2.0은 바로 집단지성을 활성 및 활용하는 것에 대한 모든 것을 의미한다.
집단지성 애플리케이션은 사용자들이 생성하는 엄청난 양의 데이터에 대한 실시간 응답, 이해, 관리에 의존하고 있다. 최근 출현하고 있는 인터넷 운영체제의 "서브시스템"들은 점점 더 데이터 서브시스템이 되어 가고 있는데, 이는 위치나 사람, 사물, 장소의 식별, 그리고 이들을 함께 엮은 의미의 실타래로 구성되어 있다. 이것은 경쟁 우위를 확보하는 새로운 수단으로 이끌고 있다: 데이터는 이제 컴퓨터 애플리케이션의 차세대 "인텔 인사이드"가 되었다.
오늘날, 우리는 이러한 통찰력이 제대로 방향을 잡았을 뿐만 아니라, 2004년에는 상상만 가능했던 영역에 적용되고 있다는 점을 깨닫고 있다. 스마트폰 혁명은 웹을 사무실에서 호주머니 속으로 이동시켰다. 집단지성 애플리케이션은 이제 더 이상 키보드를 두드리는 인간에 의해서가 아닌, 점점 더 센서에 의해 구동되고 있다. 이동전화나 카메라는 애플리케이션을 위한 눈과 귀 역할을 하고 있다; 동작 및 위치 센서는 우리가 어디에 있고, 무엇을 보고 있으며, 얼마나 빨리 움직이고 있는지 말해주고 있다. 데이터는 실시간으로 수집, 표현되며, 행동하고 있다. 데이터 참가자들의 규모는 그 크기 등급대로 증가되고 있다.
더 많은 사용자들과 센서들이 더 많은 애플리케이션과 플랫폼에 주입되면서, 개발자들은 중대한 실세계 문제들을 다룰 수 있게 되었다. 그 결과로, 웹 기회는 더 이상 산술급수적이 아닌, 기하급수적으로 증가하고 있다. 이런 이유로, 올해의 주제를 웹 스퀘어드로 정했다. 1900-2004년에 성냥에 불을 붙였다면, 2005-2009년은 불이 도화선으로 옮겨갔고 2010 은 폭발하게 될 것이다.
우리가 최초로 "웹 2.0"이란 용어를 소개한 이후로, 사람들은 그 다음은 무엇인지 질문하고 있다. 웹 2.0 이 일종의 소프트웨어 버전(닷컴 붕괴 후, 웹의 재림에 관한 논쟁보다는)을 의미했다는 가정하에 우리는 끊임없이 "웹 3.0"에 대해 질문을 받고 있다. 시만틱 웹인가요? 소셜 웹인가요? 모바일 웹인가요? 아니면 일종의 가상현실을 말하는 것인가요?
웹은 이 모든 것이며 그 이상을 의미한다.
웹은 더 이상 세상에 있는 무엇인가를 묘사하는 정적인 HTML 페이지들의 집합체가 아니다. 웹은 점차적으로 세상 그 자체가 되어가고 있다. 즉, 세상에 있는 모든 사람들과 사물들이 지능적으로 수집되고 처리되는 데이터의 아우라(aura)인 "정보 그림자(Information shadow)" 를 발산하고 있는데, 이는 놀랄 만한 기회와 정신을 어지럽힐 정도의 암시성을 제공하고 있다. 웹 스퀘어드는 바로 이러한 현상을 탐구하는 방식이다.
집단지성의 재정의: 새로운 감각 입력
웹이 어디로 가는지 이해하기 위해 웹 2.0에 근간에 있는 기본적인 아이디어 중 하나인, 이른바 성공적인 네트워크 애플리케이션들이란 집단지성을 이용하기 위한 시스템이다 라는 내용을 다시 살펴보자.
현재 많은 사람들이 "크라우드소싱"의 관점에서 이 아이디어를 이해하고 있다. 크라우드소싱이란 대규모 그룹의 사람들이 개별 참가자들에 의해 제공되는 것을 훨씬 넘어서는 가치를 지닌 집단적 작업을 창조할 수 있다는 개념이다. 전체적으로 보면 웹은 크라우드소싱의 놀랄만한 산물이다. 웹은 이베이, 크레이그리스트에서는 시장이 되었고, 유튜브와 플리커에서는 혼합된 미디어 컬렉션, 그리고 트위터, 마이스페이스 그리고 페이스북에서는 거대한 개인적인 삶의 흐름의 집합체가 되었다.
또한 많은 사람들이, 애플리케이션은 특정한 업무를 수행하도록 사용자들을 인도하는 방식으로 구축될 수 있다고 이해하고 있다. 온라인 백과사전(위키피디아)의 구축, 온라인 카탈로그에 대한 논평(아마존), 지도상에 데이터 포인트를 추가하는 작업(많은 웹 지도 애플리케이션), 혹은 가장 인기 있는 뉴스를 찾아내는 작업(디그, 트와인)등은 바로 이러한 전형적인 예라 할 수 있다. 아마존의 메카니컬 터크(Mechanical Turk)는 컴퓨터 만으로는 수행하기 어려운 업무를 사람들이 처리하도록 하기 위한 보편화된 플랫폼을 제공하는 형태로 지금까지 발전해 왔다.
그런데 이러한 것들이 정말 우리가 말하는 집단지성을 뜻하는 것일까? 과연 지성의 정의가 주변 환경과 반응하며 학습해 나가는 유기체의 특성이라는 것 하나만 존재하는 것일까? (지금 당장은, 자가인식에 대한 문제는 완전히 논외로 두고 있음을 염두에 두자.)
웹(단지 월드 와이드 웹으로서 공식적으로 알려진 PC 기반의 애플리케이션이 아닌, 연결된 모든 장치와 애플리케이션의 네트워크로서 광범위하게 정의되는 웹)을 신생아라고 생각해 보자. 신생아는 볼 수는 있지만, 인지할 수 없다. 느낄 수는 있지만, 입을 대기 전까지는 그것이 무엇인지 알지 못한다. 미소 짓는 부모가 하는 말을 들을 수는 있겠지만, 이해할 수는 없다. 신생아는 감각이라는 바다에 빠져 있지만, 이해할 수 있는 것은 거의 없으며 주변 환경을 제어하지 못한다.
점차적으로, 세계는 이성적이 되어가고 있다. 신생아는 자신이 흡수하는 여러 감각들을 조정하고, 소음으로부터 신호를 걸러내며, 새로운 기술을 배우고, 한 때는 힘들어했던 일들을 자동화하듯 쉽게 해결하게 된다.
이 시점에서 이런 질문을 해보자. 과연 웹은 성장해 가면서 똑똑해질까?
현재 웹에서 국제공용어로 통하고 있는 검색에 대해 생각해보자. 브라이언 핑커톤(Brian Pinkerton)의 웹크롤러(webcrawler)로 시작된 최초의 검색 엔진은, 말하자면 닥치는 대로 모든 것을 물고 늘어지는 식이었다. 게걸스럽게 링크의 뒤를 따라가, 발견한 모든 것을 먹어 치웠다. 키워드와 일치하는 모든 내용을 일일이 하나씩 비교해가며 순위를 정했다.
1998년, 래리 페이지(Larry Page)와 세르게이 브린(Sergey Brin)은 한 가지 돌파구를 찾아냈다. 즉, 링크는 단순히 새로운 콘텐츠를 찾아내는 수단이 아니라, 좀 더 세밀한 자연어 문법과 연결해서 그 순위를 정하는 수단이라는 점을 깨달은 것이다. 본질적으로, 모든 링크는 하나의 득표수가 되어가고 있고, 일반 사람들보다는 지식을 가진 사람들로부터의 득표수(순서대로 투표하는 사람들의 질과 수에 의해 측정되는)가 더 중요해지고 있다.
현대의 검색 엔진들은 검색 결과를 산출하기 위해 수 백 가지의 순위선정 기준과 복잡한 알고리즘을 사용하고 있다. 데이터 소스들 중 단연 돋보이는 것은 검색 용어의 빈도수와 검색 결과에 대한 사용자들의 클릭 수 그리고 개인별 맞춤 검색과 브라우징 기록에 의해 생성되는 피드백 루프이다. 예를 들어, 다수의 사용자들이 특정 검색 결과 페이지 상의 첫 번째 항목보다 다섯 번째 항목을 클릭하기 시작했다면, 구글의 알고리즘은 이를 다섯 번째 것이 첫 번째 것보다 더 낫다는 신호로 받아들여 최종적으로 검색 결과를 조정한다.
이제 좀 더 현대적인 검색 애플리케이션인 아이폰을 위한 구글 모바일 App를 고려해보자. 이 애플리케이션은 전화기를 귀로 가져가는 움직임을 탐지해 자동으로 음성 인식 모드로 전환한다. 아이폰은 목소리를 듣기 위해 마이크로폰을 사용하고, 음성 인식 데이터베이스와 알고리즘 뿐만 아니라, 검색 데이터베이스에서 가장 빈번하게 검색되는 용어와의 연관성을 참조해서 말하고 있는 내용을 해독한다. 또한 GPS나 송신탑의 삼각측량법을 이용해서 현 위치를 탐색한다. "피자"란 단어를 검색할 경우, 여러분이 원하는 검색 결과는 현 위치에서 가장 가까운 피자 식당의 이름, 위치 그리고 연락처 정보일 것이다.
뜻하지 않게, 우리는 키보드와 형식적인 문법을 사용해서 검색을 하는 것이 아니라, 웹과 대화를 하게 되었다. 명시적으로 말할 필요 없이 웹은 뭔가(가령 현재 위치 같은)를 이해하기 충분할 만큼 똑똑해지고 있으며, 이것은 단지 시작일 뿐이다.
그리고 GPS 좌표와 주소를 매핑하는 것처럼, 애플리케이션이 참조하는 일부 데이터베이스는 애플리케이션을 "가르치고" 있다. 반면, 음성 인식과 같은 다른 애플리케이션들은 크라우드소싱으로 만들어진 대규모로 처리되는 데이터 집합에 의해 "학습"을 한다.
분명한 점은, 이런 것들이 우리가 몇 년 전에 보았던 것 이상으로 "똑똑한" 시스템이라는 사실이다. 음성인식과 검색, 검색결과와 위치를 조율하는 것은, 신생아가 조금씩 주변의 사물을 인식하는 것과 흡사하다. 웹은 계속 성장하고 있으며, 우리 모두가 웹의 집단적인 부모가 되어가고 있다.
협동하는 데이터 서브시스템
초기 웹 2.0에 대한 분석에서, 우리는 미래의 "인터넷 운영체제"는 일련의 상호 운영되는 데이터 서브시스템들로 구성될 것이라고 예상했다. 구글 모바일 애플리케이션은 이러한 데이터로 구동되는 운영체제의 작동 방식에 대한 한 가지 예를 보여주고 있다.
이 경우, 모든 데이터 서브시스템들은 구글 이라는 하나의 벤더에 의해 소유된다. 이와는 다르게 애플의 iPhoto "09의 경우에는, 애플 자신의 클라우드 서비스 뿐만 아니라 플리커와 구글 맵을 통합하고 있고, 애플리케이션은 여러 벤더의 클라우드 데이터베이스 서비스를 사용하고 있다.
지난 2003년 우리가 최초로 언급했듯이, 데이터는 차세대 컴퓨터 애플리케이션의 "인텔 인사이드"이다. 즉, 애플리케이션이 동작하는데 필요한 유일한 데이터 소스를 한 회사가 점유하고 있다면, 그 회사는 자신의 데이터 사용에 대해 독점권을 발휘하게 될 것이다. 특히, 데이터베이스가 사용자들의 참여로 생성되었다면, 시장 리더들은 자신들의 데이터베이스의 가치와 크기가 시장에 막 진입한 신생 회사들보다 더 빠르게 성장함에 따라 수익이 증가하는 것을 보게 될 것이다.
우리는 웹 2.0 시대를 데이터 자산을 제어하고 획득하기 위한 하나의 경쟁으로 보고 있다. 이러한 자산들 일부(이베이에 있는 많은 수의 판매자 목록이나 크레이그리스트에서 분류된 많은 수의 광고)는 애플리케이션에 특화되어 있다. 하지만 다른 자산들은 이미 기본적인 시스템 서비스의 특성으로 자리를 굳혔다.
인터넷의 기간 서비스인 DNS의 도메인 등록을 예로 들어보자. 혹은 앨범과 노래에 대한 메타데이터를 찾는 모든 음악 애플리케이션에 의해 사용되는 CDDB를 고려해보자. 나브텍(Navteq)과 텔레아틀라스(TeleAtlas) 같은 업체들이 제공하는 데이터에 대한 매핑은 사실상 모든 온라인 매핑 애플리케이션에 의해 사용되고 있다.
지금도 소셜 그래프를 소유하기 위한 경쟁이 진행되고 있다. 하지만 이것이 모두에게 개방될 필요가 있을 정도로 기본적인 서비스인지 여부를 짚고 넘어가야 한다.
오늘날의 연약하고 혼잡한 통로에 의해 호환되지 않는 수 백 개의 이메일 시스템들로 소셜 네트워킹이 합쳐진 것처럼 15년 전 이메일이 산산조각이 났던 사실을 잊기는 쉽다. 그리고 이러한 시스템 중의 하나인 인터넷 RFC 822 이메일은 교환을 위한 훌륭한 표준이 되었다.
우리는 핵심적인 인터넷 유틸리티와 서브시스템들에서 비슷한 표준화가 나타나길 기대한다. 승자독식의 시장에서 경쟁하는 벤더들은 협력 회사들의 최상의 데이터 서브시스템으로부터 시스템을 구축할 수 있도록 함께 할 것을 조언 받고 있다.
초기 웹 2.0에 대한 분석에서, 우리는 미래의 "인터넷 운영체제"는 일련의 상호 운영되는 데이터 서브시스템들로 구성될 것이라고 예상했다. 구글 모바일 애플리케이션은 이러한 데이터로 구동되는 운영체제의 작동 방식에 대한 한 가지 예를 보여주고 있다.
이 경우, 모든 데이터 서브시스템들은 구글 이라는 하나의 벤더에 의해 소유된다. 이와는 다르게 애플의 iPhoto "09의 경우에는, 애플 자신의 클라우드 서비스 뿐만 아니라 플리커와 구글 맵을 통합하고 있고, 애플리케이션은 여러 벤더의 클라우드 데이터베이스 서비스를 사용하고 있다.
지난 2003년 우리가 최초로 언급했듯이, 데이터는 차세대 컴퓨터 애플리케이션의 "인텔 인사이드"이다. 즉, 애플리케이션이 동작하는데 필요한 유일한 데이터 소스를 한 회사가 점유하고 있다면, 그 회사는 자신의 데이터 사용에 대해 독점권을 발휘하게 될 것이다. 특히, 데이터베이스가 사용자들의 참여로 생성되었다면, 시장 리더들은 자신들의 데이터베이스의 가치와 크기가 시장에 막 진입한 신생 회사들보다 더 빠르게 성장함에 따라 수익이 증가하는 것을 보게 될 것이다.
우리는 웹 2.0 시대를 데이터 자산을 제어하고 획득하기 위한 하나의 경쟁으로 보고 있다. 이러한 자산들 일부(이베이에 있는 많은 수의 판매자 목록이나 크레이그리스트에서 분류된 많은 수의 광고)는 애플리케이션에 특화되어 있다. 하지만 다른 자산들은 이미 기본적인 시스템 서비스의 특성으로 자리를 굳혔다.
인터넷의 기간 서비스인 DNS의 도메인 등록을 예로 들어보자. 혹은 앨범과 노래에 대한 메타데이터를 찾는 모든 음악 애플리케이션에 의해 사용되는 CDDB를 고려해보자. 나브텍(Navteq)과 텔레아틀라스(TeleAtlas) 같은 업체들이 제공하는 데이터에 대한 매핑은 사실상 모든 온라인 매핑 애플리케이션에 의해 사용되고 있다.
지금도 소셜 그래프를 소유하기 위한 경쟁이 진행되고 있다. 하지만 이것이 모두에게 개방될 필요가 있을 정도로 기본적인 서비스인지 여부를 짚고 넘어가야 한다.
오늘날의 연약하고 혼잡한 통로에 의해 호환되지 않는 수 백 개의 이메일 시스템들로 소셜 네트워킹이 합쳐진 것처럼 15년 전 이메일이 산산조각이 났던 사실을 잊기는 쉽다. 그리고 이러한 시스템 중의 하나인 인터넷 RFC 822 이메일은 교환을 위한 훌륭한 표준이 되었다.
우리는 핵심적인 인터넷 유틸리티와 서브시스템들에서 비슷한 표준화가 나타나길 기대한다. 승자독식의 시장에서 경쟁하는 벤더들은 협력 회사들의 최상의 데이터 서브시스템으로부터 시스템을 구축할 수 있도록 함께 할 것을 조언 받고 있다.
웹의 학습 방식: 명시적 vs. 함축적 의미
웹은 어떤 식으로 학습을 할까? 일부 사람들은 컴퓨터 프로그램들이 의미를 이해하고 반응하는 것을 상상하고 있는데, 이러한 의미는 일부 특별한 분류방식으로 암호화될 필요가 있다. 하지만 실제로 우리 눈앞에 있는 것은 데이터 본체로부터 "추리"에 의해 학습되는 의미이다.
음성 인식과 컴퓨터 비젼은 모두 이러한 종류의 기계 학습의 훌륭한 예라 할 수 있다. 하지만, 중요한 점은 기계 학습 기술은 센서 데이터를 훨씬 뛰어 넘는 곳에까지 적용된다는 사실이다. 예를 들어, 구글의 광고 옥션은 학습 시스템이며, 기계 학습 알고리즘에 의해 실시간으로 최적의 광고 위치와 가격이 만들어진다.
또 다른 경우, 의미는 컴퓨터를 "가르치기"도 한다. 즉, 애플리케이션에 하나의 구조화된 데이터 셋과 다른 데이터 셋 사이의 매핑이 주어진다. 예를 들어, 거리의 주소와 GPS 좌표간의 제휴는 학습된다기 보다는 가르치는 것에 더 가깝다. 두 데이터 셋 모두 구조화됐지만, 이들을 연결하기 위해서는 통로가 필요하다.
또한 두 데이터 셋 간의 연결을 인지하는 방법을 애플리케이션에게 가르침으로써 구조화되지 않은 데이터에 구조성을 부여하는 것도 가능하다. 예를 들어, 아이폰 애플리케이션인 You R Here는 이러한 두 가지 접근법을 교묘히 결합하고 있다. 아이폰 카메라를 사용해서 공원의 입구에 있는 안내도나 다른 자전거 주행도 같은, 구글맵과 같은 일반적인 매핑 애플리케이션에는 없는 세부정보를 담은 지도의 사진을 찍는다. 그리고 아이폰의 GPS를 사용해 지도상에서 현재 위치를 설정한 뒤, 한참 걸어간 후에 멈춰서 두 번째 지점을 설정한다. 그리고 나면 구글맵에서 처럼, 아이폰을 이용해서 사용자 정의 지도의 이미지상에서 자신의 위치를 쉽게 추적할 수 있다.
웹에서 가장 근본적이며 유용한 서비스 중 일부는, 일단 인지를 하고 나서 처음에는 구조화되지 않은 것처럼 보이는 데이터에서 미처 보지 못한 규칙을 가르치는 방식으로 만들어져 왔다.
타이 칸(Ti Kan), 스티브 쉬러프(Steve Scherf), 그리고 CDDB의 창시자 그레이엄 톨(Graham Toal)은 CD의 트랙 정보가 가수, 앨범, 그리고 노래제목과 상관관계를 맺을 수 있는 유일한 서명을 형성한다는 점을 깨달았다. 래리 페이지와 세르게이 브린은 링크가 득표수라는 점을 깨달았다. Wesabe의 마크 헤드런드(Marc Hedlund)는 모든 신용카드 결재 또한 득표수이며, 거기에는 동일한 가맹점을 반복적으로 방문한다는 의미가 숨어 있음을 깨달았다. 페이스북의 마크 주커버그(Mark Zuckerberg)는 온라인상의 친구관계는 실제로 일반화된 소셜 그래프(Social Graph)를 구성한다는 점을 깨달았다. 이것 들은 처음에는 구조화되지 않은 것처럼 보이던 데이터를 인간과 기계 모두를 사용해서 구조화된 데이터로 변모시키고 있다.
핵심 사항: 웹 2.0시대의 핵심 역량은 함축된 메타데이터를 찾아내어 이를 둘러싸고 있는 생태계를 육성하는 메타데이터를 잡아내기 위한 데이터베이스를 구축하는 것이다.
웹과 현실 세계의 조우: "정보 그림자(Information Shadow)"와 사물의 인터넷(Internet of Things)
"센서 기반 애플리케이션"이라고 하면, 많은 사람들은 RFID 태그나 ZigBee 모듈로 구동되는 애플리케이션의 세계를 떠올릴 것이다. 하지만 이러한 미래는 그리 가까이 있지 않으며, 배포 테스트나 소수의 초기 단계 애플리케이션에서만 현존하고 있다. 그런데 많은 사람이 놓치고 있는 점이 하나 있는데, 바로 센서 혁명이 이미 얼마나 진행됐느냐는 점이다. 센서 혁명은 모바일 시장의 감춰진 얼굴이자 가장 폭발적인 기회라 할 수 있다.
오늘날의 스마트폰에는 마이크로폰, 카메라, 동작 센서, 근접 센서, 위치 센서(GPS, 송신탑의 삼각측량, 심지어는 나침반까지)가 내장되어 있다. 이러한 센서들은 독립형 애플리케이션의 사용자 인터페이스에 혁명을 가져왔다. 이의 전형적인 예가 바로 불기만 하면 되는 아이폰용 오카리나(Smule"s Ocarina)이다. 하지만 모바일 애플리케이션들은 연결된 애플리캐이션 이라는 점을 잊지 말아야 한다. 웹 2.0의 근본적인 교훈은 웹이나 이동전화기반의 그 어떠한 네트워크 애플리케이션에도 적용된다는 점이다. 센서기반 애플리케이션들은 더 많은 사람들이 사용하고, 좀 더 많은 사용법을 창조해내는 피드백 루프를 생성하는 데이터를 수집하면서 개선되도록 설계될 수 있다. 구글 모바일 App에 있는 음성 인식은 이러한 애플리케이션 중 하나이다. 인터넷에 연결된 새로운 GPS 애플리케이션들 또한 피드백 루프가 내장되어 있어서, 현재 속도를 보고하고 이 정보를 사용해서 전방의 교통정보에 근거해 도착 시간을 추정한다. 오늘날, 교통 패턴은 대략적인 추정되고 있는데, 앞으로는 실시간으로 측정될 것이다.
망(Net)은 생각 이상으로 빠른 속도로 똑똑해지고 있다. 사진에 붙는 지오태깅(geotagging)을 고려해보자. 초기에는 사용자들이 태그를 부착해서 사진과 위치정보 간의 관계를 컴퓨터에게 알려줬다. 모든 사진에 지오태그가 부착되는 그 날, 카메라들은 그 위치를 알게 될 것이며, 인간이 제공한 그 어떤 것보다 훨씬 더 정확한 위치를 알게 될 것이다.
그리고 하나의 데이터 셋에서 정확도가 커질수록 다른 데이터 셋의 정확도도 높아진다. 지오태그가 부착된 플리커 사진에 의해 생성된 아래 지도가 얼마나 정확한지 살펴보자. 수 억장의 사진이 제공된다면 이 지도는 얼마나 더 정확해질까?
미국의 플리커 지오태그 지도
http://flickr.com/photos/straup/2972130238/
망의 시각센서 네트워크를 위한 보조도구들은 위치에 제한받지 않을 것이다.
이것들은 초기 상태로 남아있지만, 애플 iPhoto "09의 안면인식은 꽤 훌륭하다. 과연 인식하지 않은 사람들만 보여줄 수 있는 시스템의 출현을 위해 이름을 부착한 얼굴이 충분해지는 시점은 언제가 될까? (애플이 시스템 서비스로 이러한 데이터를 제공할지 여부는 여전히 의문으로 남아있다. 또한 다른 누군가가 네트워크 서비스로 제공할지 여부도 확실치 않다.)
텍사스의 플리커 지오태그 지도
http://flickr.com/photos/straup/2971287541/
안드로이드를 위한 위키튜드(Wikitude) 여행 가이드 애플리케이션은 훨씬 더 향상된 이미지 인식을 한다. 이 애플리케이션은 이동전화 카메라로 기념물이나 다른 흥미로운 장소를 찍은 지점을 자신의 온라인 데이터베이스에서 찾는다. 화면에는 카메라가 찍은 것은 물론, 현재 여러분이 보고 있는 것에 대한 추가 정보까지 표시된다. 즉, 헤드업 디스플레이 기능이 실현되고 있는 것이다. 이 애플리케이션은 미래의 "증강현실(augmented reality)"의 첫 발을 내딛고 있는데, 여러분이 현재 보고 있는 장소를 추적하기 위해 나침반을 사용하면서, 관심 있는 지점까지의 거리를 겹치는 방식을 사용한다. 이 이동전화를 사용해서 관심 있는 지점 근처의 지역을 한 바퀴 둘러볼 수도 있다.
Layer는 이러한 아이디어를 더욱 발전시켜, 이동전화 카메라를 통해 본 "증강현실" 콘텐츠의 다중 레이어를 위한 프레임워크를 약속하고 있다.
센서기반의 애플리케이션이 초능력을 준다고 생각해보자. 다크슬라이드(Darkslide)는 슈퍼맨 같은 시력을 선사해서 여러분 근처에 있는 사진을 보여주고 있다. 아이폰 트위터 애플리케이션은 "근처에 있는 최근의 트윗을 찾아" 초강력 청력을 부여해서 주변에서 진행되고 있는 대화를 고를 수 있게 한다.
Photosynth, Gigapixel Photography,그리고 Infinite Image
센서 데이터와 기계학습의 증가는 가상의 세계 재건축과 창조적인 표현에 있어 새로운 개척자에게 인도할 것이다.
마이크로소프트의 Photosynth는 크라우드소싱으로 만들어진 사진들을 3D 이미지로 합성하는 컴퓨터의 능력을 여실히 보여주고 있다. Gigapixel photography은 근처에 있는 사람들에게 조차도 보이지 않는 세부적인 화면을 보여준다. 어도비의 Infinite Image는 좀 더 놀랄만한 컴퓨터의 능력을 보여주고 있는데, 한 무리의 사진들을 이용해 존재하지 않는 가상적인 세상을 완벽한 3D로 재현하고 있다. 아래의 비디오는 보게 되면 믿게 된다는 사실을 여실히 증명하고 있다.
센서 데이터와 기계학습의 증가는 가상의 세계 재건축과 창조적인 표현에 있어 새로운 개척자에게 인도할 것이다.
마이크로소프트의 Photosynth는 크라우드소싱으로 만들어진 사진들을 3D 이미지로 합성하는 컴퓨터의 능력을 여실히 보여주고 있다. Gigapixel photography은 근처에 있는 사람들에게 조차도 보이지 않는 세부적인 화면을 보여준다. 어도비의 Infinite Image는 좀 더 놀랄만한 컴퓨터의 능력을 보여주고 있는데, 한 무리의 사진들을 이용해 존재하지 않는 가상적인 세상을 완벽한 3D로 재현하고 있다. 아래의 비디오는 보게 되면 믿게 된다는 사실을 여실히 증명하고 있다.
이 모든 해결책들은 ThingM의 마이크 쿠니아브스키(Mike Kuniavsky)가 언급했던 사실을 반영하고 있다. 그는 실 세계의 사물들은 사이버공간에서 "정보 그림자"를 갖고 있다고 주장했다. 예를 들어, 책은 아마존, 구글 북서치, 굿리드(Goodreads), 쉘파리(Shelfari) 그리고 라이브러리씽(LibraryThing), 이베이, 북무우취(BookMooch), 트위터, 그리고 수 천개의 블로그 상에서 정보 그림자를 갖고 있다.
노래는 아이튠, 아마존, 랩소디(Rhapsody), 마이스페이스, 페이스북에서 정보 그림자를 가지고 있다. 한 개인의 경우 수 많은 이메일, 인스턴스 메시지, 전화통화, 트윗, 블로그 포스팅, 사진, 비디오 그리고 정부 문서에서까지 정보 그림자를 가지고 있다. 슈퍼마켓 선반에 놓인 상품, 딜러의 차고에 있는 자동차, 하역장에 있는 새로 채굴된 붕소, 작은 마을의 대로변에 있는 상점 등 모든 것은 현재 정보 그림자를 갖고 있다.
대부분의 경우, 이러한 정보 그림자들은 ISBN이나 ASIN, 부품번호 혹은 주민번호, 자동차 번호 등과 같은 유일한 식별자에 의해 실 세계에 있는 사물이나 사람들과 긴밀히 연결되어 있다. 다른 형태의 식별자도 존재한다. 이름에 주소나 전화번호를 결합하거나, 이름과 사진을 결합한 것 그리고 아주 확실한 알리바이 조차도 처참하게 무너뜨릴 수 있는 특정 지역으로부터 걸려온 전화와 같은 것들도 유일성을 나타낼 수 있다.
"사물의 인터넷"에 관해 말하는 많은 사람들은 일상생활에서 사용되는 물체에 IP 주소와 슈퍼 RFID 칩이 결합될 것이라고 가정하고 있다. 즉, 사물의 인터넷을 구현하기 위해서는 모든 물체가 유일한 식별자를 가져야만 한다고 가정하고 있다.
웹 2.0 감성이 우리에게 말하고 있는 것은 다양한 종류의 센서 데이터의 기여에 의해 사물의 인터넷에 도달할 것이며, 기계 학습 애플리케이션들은 자신에게 유입된 데이터를 점점 더 확실히 이해하게 될 것이라는 점이다. 사물의 인터넷이라는 흐름에 합류하기 위해 슈퍼마켓 선반에 있는 한 병의 와인에까지 RFID칩을 붙일 필요는 없다. 상표를 찍은 사진만으로도 충분하다. 나머지는 이동전화, 이미지 인식, 검색 그리고 감각적인 웹이 맡게 될 것이다. 즉, 슈퍼마켓에 있는 각 상품에 기계가 인식할 수 있는 유일한 ID가 부착될 때까지 기다리지 않아도 된다. 대신, 바코드, 사진태그 그리고 부르트포싱(brute0forcing) 같은 간단한 해킹기술을 응용해서 식별할 수 있다.
제프 조나스(Jeff Jonas)는 신원 확인 작업을 하면서 아주 흥미진진한 사실을 언급했다. 조나스의 작업 중 일부는 다양한 소스들로부터 유명한 미국 사람들에 대한 데이터베이스를 구축하는 것이었다. 시스템이 모든 변동사항을 식별할 만큼 충분한 정보를 보유하기 전에, 그의 데이터베이스에는 이미 6억3천만 건 정도의 "신원"을 확보하고 있었다. 그런데 특정한 순간에 데이터베이스가 학습을 시작하면서 용량이 줄어들기 시작했다. 신규로 데이터가 들어감에 따라 데이터베이스는 커지기는 커녕, 더 작아졌다. 6억 3천만에 3천만 건이 더해져서 6 억 건의 데이터가 만들어졌는데, "컨텍스트 누적(context accumulation)" 이라는 인지 계산법에 의해서 이런 마술과 같은 일이 일어난 것이다.
정보 그림자가 두터워짐에 따라, 좀 더 견고하고, 명시적인 메타데이터에 대한 요구는 감소되고 있다. 카메라와 마이크로폰은 웹의 눈과 귀가 되고 있고, 모니터 센서, 근접센서, GPS는 위치인식은 감각기관이 되어가고 있다. 정말, 웹이라는 신생아는 계속 자라고 있다. 우리는 인터넷과 만나고 있으며, 우리가 바로 인터넷이다.
센서와 모니터링 프로그램들은 단독적이 아닌, 자신들의 인간 파트너와 한 조를 이루며 동작한다. 우리는 중요하다고 생각되는 얼굴을 인식하도록 사진 프로그램을 가르치고, 관심 있는 뉴스를 공유하며, 트윗에 태그를 덧붙여 좀 더 쉽게 분류해서 정리할 수 있다. 우리 자신을 위해 가치를 추가하면서, 소셜 웹에도 역시 가치를 추가하고 있다. 디바이스들이 우리의 활동영역을 넓히고 있고, 우리 역시 디바이스의 영역을 확장하고 있다.
이러한 현상은 소비자 웹에만 국한되지 않는다. IBM의 스마터 플라넷 이니셔티브와 나사(NASA)와 시스코의 "planetary skin" 프로젝트는 비즈니스가 센서 웹에 의해 얼마나 심도있게 변형될 것인지를 보여주고 있다. 정유회사, 제철회사, 공장 그리고 공급망 들은 웹 애플리케이션에서 볼 수 있는 것과 정확히 동일한 종류의 기계 학습 알고리즘과 센서로 무장하고 있다.
뻔하디 뻔한 대기업들의 선언에서는 미래가 명확히 보이고 있지 않지만, 초기 수용자들과 "알파 긱스(alpha geeks)"의 솜씨 좋은 최적화에서는 명확히 보이고 있다. 레이다 블로거인 넷 토킹턴(Nat Torkington)은 웰링턴에서 만났던 택시기사 이야기를 해주고 있는데, 이 택시기사는 6주 동안에 태운 손님들의 기록(GPS, 날씨, 승객 그리고 다른 세가지 변수)을 컴퓨터에 저장해서, 하루 중 손님이 제일 많은 특정 시간을 알아내기 위해 몇 가지 분석을 했다고 한다. 이 분석 결과를 이용해서 그는 다른 택시기사에 비해 적게 일하고도 높은 수익을 거둬들일 수 있었다고 한다. 세상을 도구화하는 것은 충분히 그럴만한 가치가 있다.
데이터에 있는 패턴을 보기 위한 데이터 분석, 시각화 그리고 다른 기술들은 점점 더 가치 있는 기술 집합체가 되어가고 있다.
이는 물체 특히 잘 알려진 집합체(책이나 뮤직 컬렉션 같은)의 인스턴스들인, 대체품에 대한 유일한 식별자로서의 역할을 말하는 것이 아니다. 하지만 디지털 데이터에 선험적 의미를 추가하기 위한 공식적인 시스템들이, 실제로는 특성 인식을 통해 의미를 추출하는 비공식적 시스템보다 강력하지 않다는 점을 보여주는 증거가 존재한다. ISBN은 책에 대한 유일한 식별자를 제공하지만, 오히려 제목 + 저자가 피부에 더 와 닿을 것이다.
원시 센서 데이터를 체계적으로 분류하는 프로젝트들은 아마도 Astrometry 프로젝트의 노선을 따라 만들어질 것이다. 이 프로젝트의 창시자는 "우리는 과거와 미래, 그리고 현재까지 수집된 모든 유용한 천문학 이미지들을 위한 정확하고, 표준에 맞는 천문학 메타 데이터를 생성하기 위한 "천체 측정학 엔진"을 구축하고 있다"라고 주장하고 있다. 이 엔진을 사용해서 Flickr astrotagger bot은 천체의 이미지를 플리커에서 찾아 적절한 메타데이터를 제공해서, 이름으로 천문 이미지들을 검색할 수 있게 한다. 이는 산만한 센서 데이터를 정규화된 검색 데이터베이스와 매핑하는 검색 서비스인 CDDB와 유사한 서비스이다.
이러한 것들은 초기의 열성가들에 의해 만들어졌다. 그들은 기업가들이 동일한 원칙을 새로운 비즈니스 기회에 적용하는 세계가 올 것을 예고했다. 우리가 살고 있는 세계에서 센서가 점점 더 활성화됨에 따라, 그들의 데이터 흐름으로부터 의미와 가치가 얼마만큼 추출될 수 있는지에 대한 놀랄만한 계시가 나올 것이다.
이른바 "스마트 전기 그리드"를 생각해보자. 에너지 관련 센서 데이터를 위한 중성 백엔드 웹서비스인 AMEE의 창시자인 가빈 스타크(Gavin Stark)는 연구자들이 영국의 1200만 가구로부터 수집한 스마트 메타 데이터를 결합하면서, 각 가정에 있는 가전제품들이 유일한 에너지 서명(signature)를 가지고 있는 사실을 발견했다는 점에 주목했다. 이 에너지 서명을 이용해서 각 가전제품이 사용한 전력량 뿐만 아니라, 각각의 주요 가전제품의 모델과 제조사를 결정하는 것이 가능하다. CDDB를 소비자 가전제품으로 생각하라.
구조화되지 않은 데이터와 구조화된 데이터 셋과의 매핑은 핵심적인 웹 스퀘어드 역량이 될 것이다.
실시간의 도래: 집단 사고방식(Collective Mind)
좀 더 대화형이 되어감에 따라 검색은 더 빨라졌다. 매일 혹은 심지어 매 시간마다 검색이 필요한 수 천 만개의 사이트에 블로그들이 추가되었으나, 마이크로블로깅은 실 시간적인 갱신을 요구하고 있다. 이는 인프라와 접근법 모두에 있어 중대한 변화가 이루어지고 있음을 의미한다. 트위터에서 현재 유행하는 주제에 대해 검색을 하면, 지금 당장 무슨 일이 일어나고 있는지 보세요" 그리고 뒤이어 "검색을 시작한 이후로 42개의 결과가 더 검색되었습니다. 이 내용을 보려면 다시 검색하세요." 라는 메시지를 보게 될 것이다:
더군다나, 사용자들 역시 검색 시스템과 함께 계속 진화하고 있다. 트위터에서, 공유된 사건에 대한 실시간 검색을 활성화하는 사용자들 간의 약속인 해쉬태그를 붙여보자. 다시 한번, 여러분은 사람들의 참여가 어떤 식으로 원시 데이터 스트림을 구조적으로 만드는지 보게 될 것이다.
실시간 검색은 실시간 응답을 이끌어낸다. 재 트윗된 "정보 캐스케이드(Information Cascades)"들은 트위터에서 순식간에 긴급속보 형태로 퍼져나가서, 무슨 일이 발생했는지 알고자 하는 많은 사람들을 위한 원천 소스가 되고 있다. 그리고 이것 역시 단지 시작일 뿐이다. 트위터와 페이스북의 status update 같은 서비스를 통해 웹에 새로운 데이터 소스가 추가되고 있으며, 이것들은 우리의 집단적 사고방식 상에서 실시간 지표가 되어가고 있다.
최근에 트위터에 의해 정치적 시위들이 발생하고 조정된 적이 있는 과테말라와 이란은 트위터의 영향력을 몸소 체험했다.
이러한 사실은 다음과 같은 시기 적절한 논쟁을 불러 일으키고 있다. 많은 사람들이 기술의 탈인간화 효과에 대해 걱정하고 있고, 우리 역시 같은 고민을 갖고 있다. 하지만 다른 측면에서 보면, 기술은 소통의 통로를 넓게 열어 공유된 컨텍스트를 제공하고, 궁극적으로는 정체성까지 공유하도록 이끌고 있다.
트위터는 또한 애플리케이션들이 어떻게 장치에 적응하는가에 대한 중요한 사실을 가르쳐주고 있다. 트윗은 140 글자로 제한된다; 트위터의 이러한 제한은 봇물처럼 넘쳐 흐르는 혁신을 이끌어냈다. 즉, 트위터 사용자들은 속기법(@username, #hashtag, $stockticker)을 개발했으며, 트위터 클라이언트들은 곧 클릭 가능한 링크로 변모했다. 전통적인 웹 링크에 대한 URL 속기법이 유명해졌고, 곧 클릭된 링크에 대한 데이터베이스가 새로운 실시간 분석을 가능하게 한다는 사실을 깨닫게 해주었다. 예를 들어, Bit.ly는 실시간으로 생성해낸 링크에 대한 클릭 수를 보여주고 있다.
이러한 결과로, 검색, 분석 그리고 소셜 네트워크로 대표되는 웹 서비스의 경쟁상대로 부상하고 있는 트위터 주변에 새로운 정보 계층이 구축되고 있다. 트위터는 또한 여러분이 API를 제공할 때 발생할 수 있는 것들에 대해 모바일 서비스 공급자들에게 객체 학습을 제공하고 있다. 트위터 애플리케이션 생태계로부터의 학습은 SMS와 다른 모바일 서비스, 혹은 이들을 대체하면서 성장할 수 있는 서비스를 위한 기회를 보여주고 있다.
실시간은 미디어나 모바일에 국한되지 않는다. 구글이 링크가 하나의 득표수라는 사실을 깨달았듯이, 월마트는 고객의 상품 구매도 하나의 득표수이며, 금전등록기는 이러한 득표수를 세는 센서라는 사실을 알아차렸다. 실시간 피드백 루프가 상품 목록을 관리하고 있는 것이다. 월마트를 웹 2.0 회사라고는 할 수는 없겠지만, 틀림없는 웹 스퀘어드 회사라고 할 수 있다. 이들의 사업운영에는 IT가 접목되어 있어, 고객들의 데이터에 의해 구동되고 있는데, 이로 인해 엄청난 경쟁우위를 갖게 된다. 웹 스퀘어드 기회의 대단한 점 중 하나는, 독점적인 공급망 없이도 이러한 종류의 실시간 지능을 작은 소매업자들에게 제공할 수 있다는 점이다.
말콤 글래드웰(Malcolm Gladwell)은 자신의 뉴요커 기고문에서 Tibco의 CEO이자 창업자인 바이벡 래너다이브(Vivek Ranadive)의 다음과 같은 감동적인 설명을 인용했다:
"이 세상에 있는 모든 것들은 이제 실시간화 되고 있다. 따라서 중국에서 만들어진 특정 종류의 신발이 근처에 있는 작은 상점에 진열되기까지 6개월을 기다릴 필요가 없다. 소프트웨어 덕분에 모든 것이 순식간에 일어난다"
굳이 센서에 의해 구매가 발생하지 않더라도, 실시간 정보는 비즈니스에 큰 영향을 주고 있다. 고객들이 자신들의 목적을 행동이나 말을 통해 웹에(그리고 트위터에) 게시하면, 회사들은 이를 듣고 대화에 참여해야만 한다. 컴캐스트(Comcast)라는 회사는 트위터를 이용해서 고객 서비스 접근법을 바꾸고 있으며, 다른 회사들 역시 이에 동조하고 있다.
실시간 피드백 루프에 대해 최근에 들었던 또 다른 놀라운 이야기는, 오바마 선거캠프에서 사용했던 후디니(Houdini) 시스템이다. 이 시스템은 유권자들이 실제로 투표를 하자마자 투표독려예상 목록에서 해당 투표자를 제거한다. 중요 지역에 있는 투표 감시자들은 투표자 리스트에서 줄이 그어진 이름들을 보고한다. 그리고 나서 보고된 사람들은 투표독려예상 목록에서 "사라지게"된다. (순식간에 명단이 사라지므로 이 시스템을 후디니 라고 지었다고 한다.)
후디니는 아마존의 메카니컬 터크(Mechanical Turk)에서 확실히 드러나고 있다. 센서 역할을 하는 한 그룹의 지원자들과 다중 실시간 데이터 큐는 동기화되며, 동일한 시스템에서 작동기로 사용되고 있는 다른 그룹의 지원자들을 위한 지침에 영향을 주는데 사용된다.
비즈니스는 자원할당, 고객서비스, 제품 개발을 위한 훨씬 더 효율적인 피드백 루프를 알려주는 핵심 신호로써 실시간 데이터를 이용하는 법을 배워야 한다.
결론: 문제의 본질
지금까지 언급한 내용은 여러 가지 방식으로 웹 스퀘어드 시대의 기회에서 가장 중요한 부분이 무엇이 될 것인가에 대한 하나의 서론을 얘기한 것이다.
웹을 위한 새로운 방향은, 물리적 세계와의 충돌의 과정으로, 비즈니스를 위해 엄청난 새로운 기회와 전 세계에서 가장 긴급한 문제들과의 차별성을 두기 위한 거대한 새로운 가능성을 열고 있다.
이미 이런 현상에 대한 수 백 가지의 예가 존재하고 있다(아래의 사례접수 참조). 하지만 에너지 생태계에서부터 보건의료에 대한 접근까지, 훨씬 더 큰 진전을 이뤄야 할 필요가 있는 영역이 매우 많다. 혼란에 휩싸인 작금의 금융 시스템은 말할 것도 없다. 심지어는 친규제적 환경에서도, 실시간으로 자동화된 금융 시스템이 정부의 규제 감독관들을 제쳐버렸다. 과연 우리가 소비자 인터넷으로부터 배웠던 것이 새로운 21세기 금융 규제 시스템을 위한 기초로 제 역할을 할 수 있을까? 이렇게 되기 위해서는 학습 기계, 변칙사항들을 탐지할 수 있는 알고리즘, 인원부족으로 인해 과로에 지친 규제 감독관들이 아닌, 진정으로 미래를 걱정하는 사람들의 감시가 이루어지는 투명성이 필요하다.
웹 2.0 이벤트를 시작했을 때, 우리는 "웹은 플랫폼이다"라고 단언했다. 그 이후로, 수 천 개의 비즈니스와 수 백만의 사람들이 웹이라는 플랫폼 위에 구축된 서비스와 제품들에 의해 변화되어왔다. 하지만 2009년은 웹의 역사에서 변곡점을 찍고 있다. 이제 우리가 구축했던 플랫폼의 진정한 힘을 이용할 때가 되었다. 웹은 더 이상 산업 자체가 아닌, 세상 그 자체가 되었다.
그리고 세상은 우리의 도움이 필요로 하고 있다.
세상에서 가장 급박한 문제를 해결하려고 한다면, 우리는 기술, 비즈니스 모델, 그리고 아마도 가장 중요한 항목인 개방성의 철학, 집단 지성 그리고 투명성으로 대표되는 웹의 진정한 힘이 작용하도록 만들어야 한다. 이렇게 하기 위해서, 우리는 웹을 한 단계 더 끌어올려야 한다. 이제 더 이상 점진적인 진화를 할 여유가 없다.
웹이 실 세계를 독려할 때가 왔다. 웹이 세상과 만나는, 바로 이것이 바로 웹 스퀘어드이다.
TAG :
이전 글 : About STL : C++ STL 프로그래밍(10)-알고리즘2
다음 글 : 오픈솔라리스: 드라이버 논쟁

최신 콘텐츠