IT/모바일
챗봇은 여러 차례 대화를 주고받는 멀티턴Multi-Turn 방식으로 동작합니다. 특히 우리가 만들려는 ‘내 찐친 고비’는 일상의 언어로 대화를 주고받습니다.
이렇게 언어 모델을 대화형으로 설계하는 경우 프롬프트를 어떻게 구성해야 하는지 판단하기가 혼란스럽습니다. 꼬리에 꼬리를 무는 대화의 특성상 인스트럭션, 컨텍스트,입력 데이터, 출력 지시자로 프롬프트를 구성하기가 쉽지 않기 때문입니다.
이번에는 대화형 인공지능에서 프롬프트가 갖는 의미를 살펴보고, 멀티턴 대화가 가능한 챗봇을 설계하겠습니다. 그렇게 설계한 내용은 지난 장에서 배웠던 프롬프트 엔지니어링을 활용하여 코드로 생성해 보겠습니다.
1️⃣ 대화형 언어 모델에서의 컨텍스트
언어 모델은 사용 목적에 따라 완성형 언어 모델Completion Language Models과 대화형 언어 모델Conversational Language Models로 나눌 수 있습니다. gpt-3.5-turbo-instruct 같은 완성형 모델은 사용자가 제공한 프롬프트를 이어받아 완결된 텍스트를 만드는 데 초점을 맞춥니다.
이에 반해 챗GPT 같은 대화형 언어 모델은 말 그대로 질문과 답변을 이어가면서 인간처럼 대화하는 것을 중요하게생각합니다. 이러한 점을 고려하면 대화형 언어 모델에서의 프롬프트는 완성형 언어 모델과 차이점이 존재할 수밖에 없습니다.
다음은 챗GPT에게 물어본 대화형 인공지능에서의 프롬프트의 의미입니다.


대화형 인공지능에서는 질의를 할 때마다 지금까지 나눈 모든 대화가 문맥이 되므로 프롬프트는 컨텍스트 그 자체라고 응답하고 있습니다. 다음은 오픈AI 공식 문서에 있는 대화형 챗봇의프롬프트 전송 가이드입니다
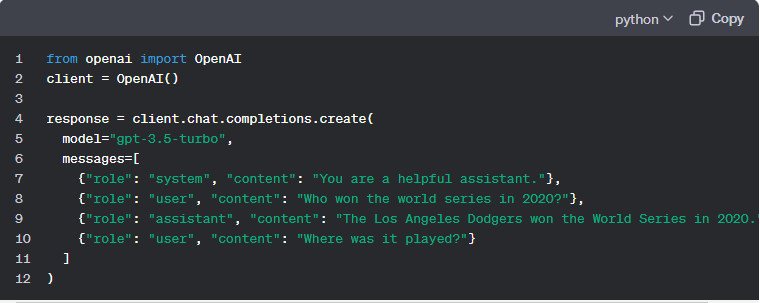
코드를 보면 user(나)의 대화 하나만 전달하는 것이 아니라 user가 질문하고 assistant가 답하고 다시 user가 질문하는 대화 전체를 API로 보내는 것을 알 수 있습니다. 앞서 말했던 프롬프트가 문맥 또는 대화 전체라는 사실이 이 예시를 통해서 잘 드러납니다.
사실, 챗GPT 채팅 사이트를 통해서 나누는 대화도 마찬가지입니다. 오픈AI에서는 각각의 대화를 ‘세션’이라고 부릅니다. 다음 화면에서 ‘챗봇 시스템 설계’, ‘프롬프트의 의미 설명’이 각각의 세션에 해당합니다
위의 세션 하나하나가 챗GPT와 나누는 대화의 전체이자 문맥입니다. 당연히 챗GPT에게 말을 걸 때마다 저 세션 안에 쌓여 있는 모든 대화가 전달됩니다(단, 대화 크기가 일정 사이즈를초과하면 잘라서 전달합니다.).
중요한 것은 우리가 만드는 인공지능과의 대화도 저렇게 설계되어야 한다는 사실입니다.
2️⃣ 챗봇 시스템 설계하기
앞서 말한 사항을 고려하면서 우리가 개발할 챗봇의 설계도를 그리고 문답 시뮬레이션을 구성해 보겠습니다.
설계도 그리기
‘문맥 저장소’를 중심으로 보면, 사용자와 언어 모델이 대화를 주고받는 과정을 다음과 같이 설계할 수 있습니다.
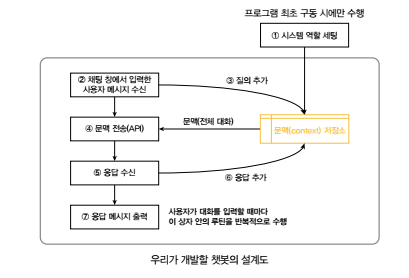
설계도에 이상이 없는지 알아보려고 오픈AI에서 예시한 월드시리즈 문답을 시뮬레이션해 보겠습니다. context는 리스트 데이터로 표현했습니다.
결국 이곳에 텍스트가 어떻게 쌓이는지가 관건이므로 대화가 진행되면서 context가 어떻게 변화하는지를 중심으로 설계도와 시뮬레이션을 번갈아 보기 바랍니다.
월드시리즈 문답 시뮬레이션
프로그램 구동
① 프로그램 구동 직후
context = [
{"role": "system", "content": "You are a helpful assistant."}
]
② 사용자가 입력한 “Who won the world series in 2020?”를 수신
③ 사용자의 메시지를 context에 추가
context = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"}
]
④ 문맥 전송: 현재 context를 openai api 입력값으로 세팅하여 전송
⑤ 응답 수신 : 아래 메시지가 포함된 response를 수신
"message": {
"role": "assistant",
"content": "The Los Angeles Dodgers won the World Series in 2020."
}
⑥ 응답 내용을 context에 추가
context = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."}
]
⑦ 채팅 창에 응답 메시지 출력
| “The Los Angeles Dodgers won the World Series in 2020 |
사용자가 채팅 창에 메시지를 다시 입력
② 사용자가 채팅 창에 “Where was it played?” 입력
③ 사용자의 메시지를 context에 추가
여기까지가 프롬프트 전송 가이드에 있는 예시를 설계도에 따라 시뮬레이션한 내용입니다. 시뮬레이션대로 잘 흘러간다면 설계도에 문제가 없는 겁니다.
이 과정을 통해 이번 사용자의 메시지 + 지금까지 나눈 모든 대화를 언어 모델의 입력값으로 한 번에 밀어 넣으면 이를 바탕으로 다음에 나올 말을 출력하는 것이 대화형 언어 모델의 작동 방식이라는 것을 알 수 있습니다.
결국 대화형 언어 모델이란 것도 근본적으로는 입출력 함수에 지나지 않으며, 단지 입력에 이전 대화까지 포함해서 마치 문맥을 이해하는 것처럼 보이게 만드는 것에 불과합니다.
앞에서챗GPT가 ‘프롬프트 = 전체 대화 = 문맥이 맞다’고 답한 이유가 이제 좀 더 명확해졌습니다.

챗GPT, 아직도 ‘사용’만 하나요?
생성형 AI 실무 개발자가 알려주는 챗GPT 200% 활용하기
이 책은 비전공자, 비개발자도 LLM을 기반으로 챗봇을 개발하는 과정을 짧은 기간 안에 효과적으로 체험하도록 고안되었습니다. 딱 필요한 만큼 다루는 파이썬, 프롬프트 엔지니어링, API를 통한 언어 모델과의 대화, 자율적 에이전트 구현, 기억 장치 사용을 단계별로 다루었습니다. 그리고 이러한 지식을 바탕으로 2023년 11월에 발표된 Assistants API 및 GPTs의 동작 원리와 구현 방식 그리고 이 모든 것을 카카오톡에 탑재하는 방법까지 낱낱이 다루었습니다.
GPT-4o-mini, LLM, GPT API, GPTs, 벡터DB…
검증된 베스트셀러가 최신 버전으로 돌아왔다!
실습 예제를 나열해 단순히 따라만 하는 게 아닌 원리와 동작 방식을 그림과 자료를 활용해 세세하게 설명했습니다. 낯선 단어도, 막막한 기능도 어디서 어떻게 쓰이는지 바닥부터 다질 수 있도록 꼼꼼하게 살펴봅니다. 생성 AI를 응용해 나만의 서비스를 개발해 보고 싶은 개발자, AI 프로덕트가 만들어지는 과정이 궁금한 기획자, AI를 더 깊이 그리고 더 넓게 학습해 보고 싶은 누구나 이 책을 통해 무겁지 않게 시작할 수 있을 것입니다.
이전 글 : [개발자 CS 기술 면접] 5. 데이터베이스 편(5/5)
다음 글 : 플러터의 필수개념 이해하기 - 아키텍처와 위젯

최신 콘텐츠