IT/모바일
챗GPTChat GPT를 처음 마주했을 때를 떠올려 보세요. 기계 속에서 사람이 답변하는 듯한 글을 자동으로 생성해 내는 모습은 놀랍고 예상치 못한 일이였죠. 챗GPT는 어떻게 이 일을 해 내는걸까요? 잘 작동하는 이유가 뭘까요? 저명한 과학자이자 계산 분야의 선구자인 스티븐 울프럼은 이렇게 이야기합니다.
➡️ 한 번에 한 단어씩 추가하는 것뿐입니다.
기본적으로 챗GPT가 늘 하는 일은 지금까지의 텍스트를 합리적으로 이어 쓰는것입니다. 여기서 ‘합리적’이란 ‘사람이 작성한 수십억 개의 웹 페이지를 읽은 누군가가 쓴 글처럼 보이는 것’을 의미합니다. 챗GPT가 사람이 쓴 듯한 글을 자동으로 생성하는 일은 놀랍고 예상치 못한 일입니다.
웹과 전자책에서 수십억 페이지에 달하는 문장을 검색한 다음, ‘The best thing about AI is its ability to’라는 텍스트가 등장하는 모든 경우를 찾아서 다음에 어떤 단어가 나올지 순식간에 알아낸다고 상상해보세요. 챗GPT는 이런 작업을 효과적으로 수행합니다. 나중에 설명하겠지만 문자 그대로 동일한 텍스트를 찾는 것이 아니라 의미상 일치하는 것을 찾습니다. 하지만 아래 그림과 같이, 한 개의 단어가 아니라 다음 단어가 될 후보와 확률probability 목록을 최종 결과로 생성합니다.

놀라운 점은 챗GPT가 글을 생성할 때 근본적으로 ‘지금까지의 텍스트를 감안하면 다음 단어는 무엇인가요?’라고 반복해서 질문하고 매번 텍스트 끝에 한 단어씩 추가한다는 것입니다.
매번 반복할 때마다 확률이 적힌 단어 목록을 얻습니다. 그렇다면 작성 중인 에세이(또는 다른 종류의 글)에 추가할 단어로 어떤 단어를 선택해야 할까요? 가장 높은 순위의 단어, 즉 확률이 가장 높은 단어를 선택해야 한다고 생각할 수 있습니다. 하지만 여기서부터 약간의 마법이 필요합니다.
왜냐하면 어떤 이유에서인지 항상 가장 높은 순위의 단어를 선택하면 대부분 창의적이지 않고, 심지어 같은 단어가 반복되는 매우 밋밋한 글이 되기 때문입니다.* 하지만 이따금 무작위로 낮은 순위의 단어를 선택하면 더 흥미로운 글이 됩니다.
* 하나씩 생성한 단어를 입력 문장 뒤에 추가해 다시 입력에 사용하는 모델을 자기회귀 모델autoregressive model이라 부릅니다. 이런 모델은 이전에 생성한 문장을 사용해 새로운 단어를 예측하기 때문에 이전 단어를 반복해 생성하는 경향이 있습니다.
여기에 무작위성이 있다는 사실은 동일한 프롬프트prompt를 여러 번 사용해도 매번 다른 글이 나올 가능성이 높다는 뜻입니다. 또한 마법의 힘을 조절하기 위해 낮은 순위의 단어가 얼마나 자주 사용되는지를 결정하는 소위 온도temperature 파라미터(매개변수)parameter가 있습니다. 에세이를 생성할 때의 온도는 0.8이 가장 좋습니다.
설명을 이어나가기 전에 언급할 것이 있습니다. 이 글에서는 완전한 챗GPT 시스템을 사용하지 않고 표준 데스크톱 컴퓨터에서 실행할 수 있을 정도로 간단한 GPT-2 시스템을 사용합니다. 따라서 이 글에 나오는 예시는 울프럼 언어 Wolfram language로 작성된 코드를 실행해 얻은 것입니다.
예를 들어 앞선 문장의 단어와 확률 목록을 구하는 방법은 다음과 같습니다.
먼저, 언어 모델을 준비합니다.

작동 방식은 나중에 신경망의 내부를 살펴본 후 설명하겠습니다. 지금은 신경망 모델을 블랙박스로 보고 예제 텍스트를 입력합니다. 그다음 모델이 출력한 확률이 높은 상위 5개 단어를 확인해보겠습니다.

다음 코드로 결과를 특정 형식의 데이터셋 dataset으로 만들 수 있습니다.
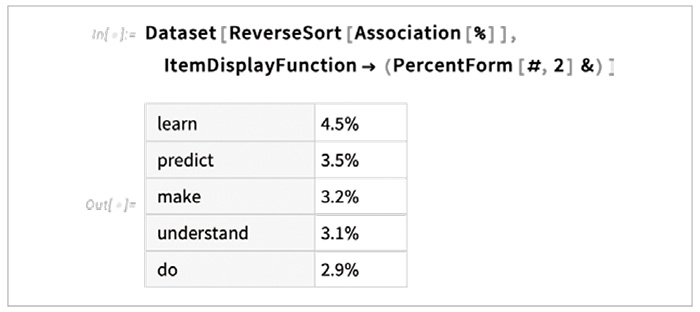
다음 코드처럼 모델의 "Decision"에 표시된 가장 높은 확률을 가진 단어를 추가하는 식으로 모델을 반복해서 적용하면 다음과 같은 결과를 얻게 됩니다.
이걸 더 오래 반복하면 어떻게 될까요?
온도 파라미터가 0인 이번 경우에는 금세 혼란스럽고 반복적인 텍스트가 생성됩니다.

하지만 확률이 높은 단어를 선택하지 않고 이따금 무작위로 다른 단어를 선택하면 어떨까요? 이번에는 온도를 0.8로 지정했습니다. 텍스트를 다시 생성하면 다음과 같은 결과가 나옵니다.

그리고 무작위로 다른 단어를 선택하기 때문에 다음 다섯 개의 예시 문장처럼 매번 결과가 달라집니다.

온도가 0.8일 때 첫 번째 단계에서 선택할 수 있는 다음 단어는 많지만, 그 확률은 매우 빠르게 감소합니다. 다음 로그-로그 log-log 그래프에 등장한 직선 형태는 언어 통계의 일반적 특징인 n-1 멱법칙 power law 감소를 보여줍니다.
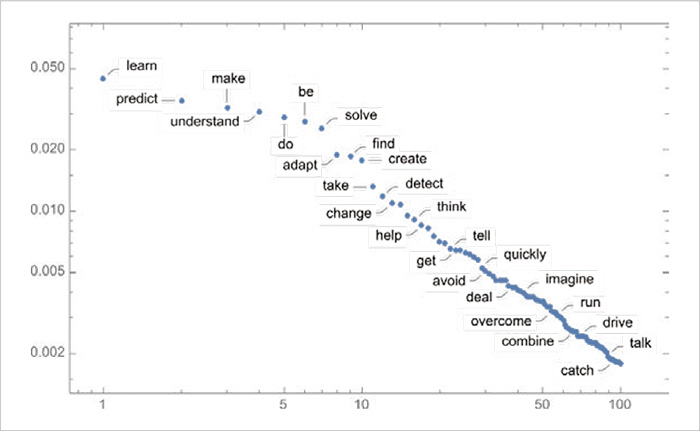
그렇다면 이 온도에서 더 오래 반복하면 어떻게 될까요?
다음 예시를 살펴보죠. 온도가 0인 경우보다는 낫지만 여전히 약간 이상합니다.

여기서는 2019년에 출시된 가장 간단한 GPT-2 모델을 사용했습니다. 새로 나온 더 큰 GPT-3 모델을 사용하면 더 좋은 결과를 얻을 수 있습니다. 다음은 GPT-3 모델에 동일한 프롬프트와 온도 0을 적용해 생성한 텍스트입니다.

다음은 온도 0.8을 사용해 만든 텍스트입니다.

챗GPT는 항상 확률에 따라 다음 단어를 선택합니다. 이때 확률은 어떻게 계산할까요? 현재 존재하는 모든 단어의 확률을 추정할 수 있는 방법이 있는걸까요?
이 글은 『스티븐 울프럼의 챗GPT 강의』에서 일부를 발췌하여 정리하였습니다.
세계적인 수학자이자 물리학자인 스티븐 울프럼 박사가 챗GPT의 작동 원리와 성공의 이유는 물론 강점과 약점을 이야기합니다. 챗GPT는 수학 계산에 매우 취약합니다. 스티븐 박사는 해결 방법으로 울프럼 언어, 즉 '계산 언어'를 활용해 계산 작업의 한계를 극복하는 방법까지 소개합니다.
챗GPT 창시자인 '샘 올트먼'의 추천 도서! 울프럼 알파 플러그인을 챗GPT에 적용하기 전과 후 결과를 비교하며 도구 활용의 잠재적이고 폭발적인 가능성은 『스티븐 울프럼의 챗GPT 강의』에서 확인해 보세요.


최신 콘텐츠