IT/모바일
UNION을 사용한 조건 분기는 SQL 초보자가 좋아하는 기술 중 하나입니다.
일반적으로 이러한 조건 분기는, WHERE 구만 조금씩 다른 여러 개의 SELECT 구문을 합쳐서, 복수의 조건에 일치하는 하나의 결과 집합을 얻고 싶을 때 사용합니다. 이러한 방법은 큰 문제를 작은 문제로 나눌 수 있다는 점에서 생각하기 쉽다는 장점이 있습니다. 따라서 조건 분기와 관련된 문제를 접할 때 가장 처음 생각할 수 있는 기본적인 방법입니다.
하지만 이런 방법은 성능적인 측면에서 굉장히 큰 단점을 가지고 있습니다. 외부적으로는 하나의 SQL 구문을 실행하는 것처럼 보이지만, 내부적으로는 여러 개의 SELECT 구문을 실행하는 실행 계획으로 해석되기 때문입니다. 따라서 테이블에 접근하는 횟수가 많아져서 I/O 비용이 크게 늘어납니다(* 저자주> 물론 예외도 있습니다. 어떤 경우가 예외인지는 10강에서 설명할 ‘UNION을 사용하는 것이 성능적으로 더 좋은 경우’에서 설명하겠습니다).
따라서 SQL에서 조건 분기를 할 때 UNION을 사용해도 좋을지 여부는 신중히 검토해야 합니다. 아무 생각 없이 무조건 UNION을 사용해서는 안 됩니다. 이번 8강에서는 UNION과 CASE를 사용한 조건 분기를 비교하면서, 어떤 경우에 어떤 것을 사용하는 것이 좋을지 알아보겠습니다.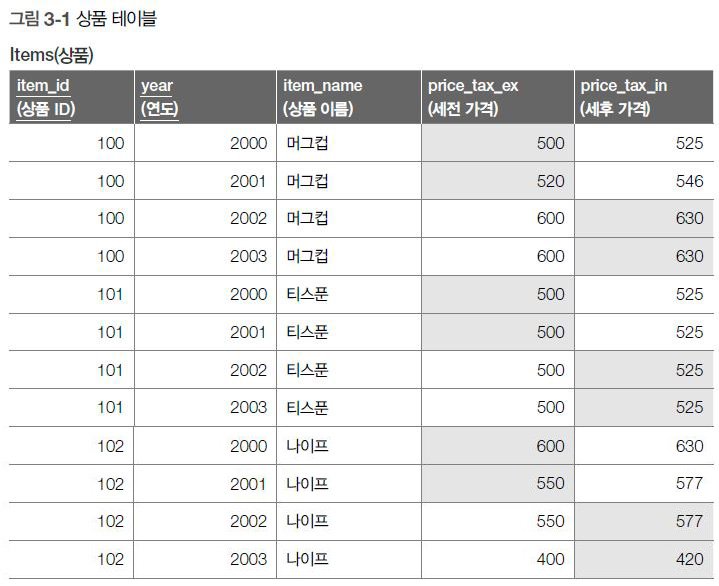
1. UNION을 사용한 조건 분기와 관련된 간단한 예제
조금 어색해 보이겠지만, 어떤 사람이 보아도 쉽게 이해할 수 있는 문제를 예제로 살펴보겠습니다.
일단 상품을 관리하는 테이블 Items가 있습니다(그림 3-1). 이 테이블은 각각의 상품에 대해서 세금이 포함된 가격과 세금이 포함되지 않은 가격을 모두 저장합니다. 그런데 2002년부터 법이 개정되면서 세금이 포함된 가격을 표시하는 게 의무가 되었습니다.
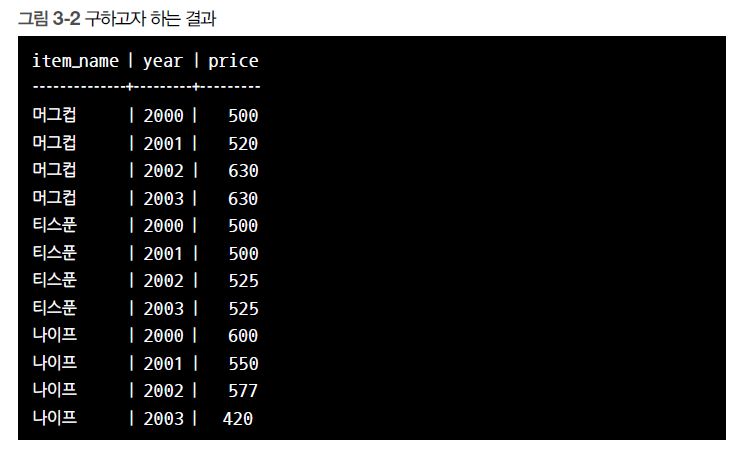
따라서 2001년까지는 세금이 포함되지 않은 가격을, 2002년부터는 세금이 포함된 가격을 ‘price(가격)’ 필드로 표시하게 되었습니다. 즉, [그림 3-1]의 색칠된 부분을 모아 [그림 3-2]처럼 출력해야 합니다. 조건 분기에 ‘year’ 필드를 사용해야 하겠다는 건 쉽게 알 수 있을 것입니다.이를 중심으로 2001년 이전과 2002년 이후를 구분해서 가격을 선택하면 됩니다. UNION을 사용하면 [코드 3-1]처럼 이러한 조건 분기를 만들 수 있습니다.

조건이 배타적이므로 중복된 레코드가 발생하지 않습니다. 쓸데없이 정렬 등의 처리를 하지 않아도 되므로 UNION ALL을 사용했습니다. 하지만 포인트는 다른 곳에 있습니다. 이 코드는 굉장히 큰 문제점을 안고 있는데요. 첫 번째 문제는 쓸데없이 길다는 것입니다. 거의 같은 두 개의 쿼리를 두 번이나 실행하고 있습니다. 이는 SQL을 쓸데없이 길고, 읽기 힘들게 만들 뿐입니다. 또한 두 번째 문제는 성능입니다.
[UNION을 사용했을 때의 실행 계획 문제]
UNION을 사용한 쿼리의 성능 문제를 명확히 하기 위해 실행 계획을 살펴보겠습니다. PostgreSQL과 Oracle의 실행 계획을 각각 [그림 3-3]과 [그림 3-4]에 표시했습니다.
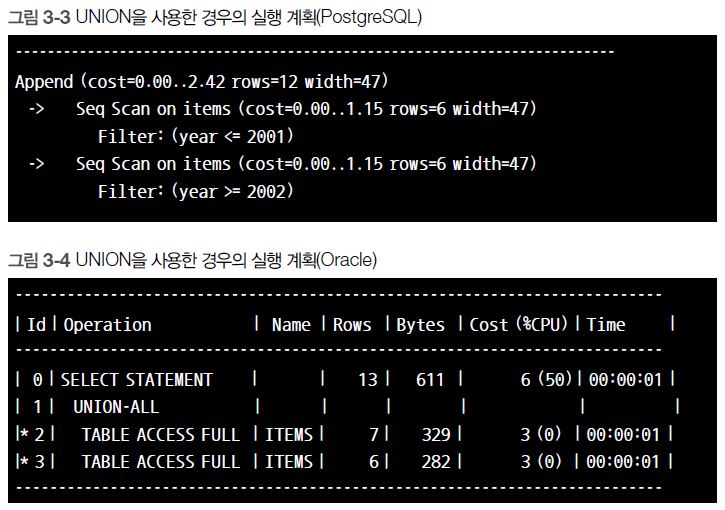
어떤 것을 사용하더라도 UNION 쿼리는 Items 테이블에 2회 접근한다는 것을 알 수 있습니다. 그리고 그때마다 TABLE ACCESS FULL이 발생하므로, 읽어들이는 비용도 테이블의 크기에 따라 선형으로 증가하게 됩니다. 물론 데이터 캐시에 테이블의 데이터가 있으면 어느 정도 그런 증상이 완화되겠지만, 테이블의 크기가 커지면 캐시 히트율이 낮아지므로 그러한 것도 기대하기 힘들어집니다.
[정확한 판단 없는 UNION 사용 회피]
간단하게 레코드 집합을 합칠 수 있다는 점에서 UNION은 굉장히 편리한 도구입니다. 따라서 UNION을 조건 분기를 위해 사용하고 싶은 유혹에 사로잡히는 것도 무리는 아닙니다. 하지만 이는 굉장히 위험한 생각입니다. 정확한 판단 없이 SELECT 구문 전체를 여러 번 사용해서 코드를 길게 만드는 것은 쓸데없는 테이블 접근을 발생시키며 SQL의 성능을 나쁘게 만듭니다. 또한 물리 자원(저장소의 I/O비용)도 쓸데없이 소비하게 됩니다.
2. WHERE 구에서 조건 분기를 하는 사람은 초보자
시스템 개발의 세계에는 앞선 사람들의 지혜와 노하우가 간단한 격언처럼 남아있습니다. 예를 들어서 “GOTO는 사용하지 않는 것이 좋다”, “데이터 구조가 코드를 결정하지만, 코드가 데이터 구조를 결정하지는 못한다”, “버그가 아니라 원래 그렇게 만든 것이다” 등처럼 말이지요. SQL에도 이러한 격언들이 있습니다. 그중에서 “조건 분기를 WHERE 구로 하는 사람들은 초보자다. 잘 하는 사람은 SELECT 구만으로 조건 분기를 한다”라는 말 이 있습니다. 지금 살펴보고 있는 문제도 SELECT 구만으로 조건 분기를 하면 다 음과 같이 최적화할 수 있습니다(코드 3-2).

이 쿼리도 [코드 3-1]의 UNION을 사용한 쿼리와 같은 결과를 출력합니다. 하지만 성능적으로 이번 쿼리가 훨씬 좋습니다(테이블의 크기가 커질수록 더 명확하게 드러난답니다).
3. SELECT 구를 사용한 조건 분기의 실행 계획
CASE 식을 사용한 쿼리의 실행 계획은 [그림 3-5]와 [그림 3-6]입니다.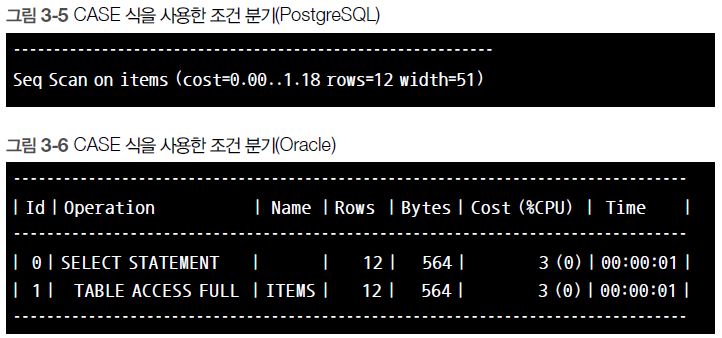
Items 테이블에 대한 접근이 1회로 줄어든 것을 확인할 수 있습니다. 이전의 UNION을 사용한 구문보다 성능이 2배 좋아졌다고 할 수 있겠죠?(* 저자주> 이전에 설명했던 것처럼 버퍼 캐시의 영향도 생각해야 하고, 사실 I/O 비용과 실행 시간은 선형 관계에 있지 않으므로, 단순하게 결론 내는 것은 불가능합니다. 어디까지나 간단한 설명이라고 생각해주세요!) 또한 SQL 구문 자체의 가독성도 굉장히 좋아졌습니다.
이처럼, SQL 구문의 성능이 좋은지 나쁜지는 반드시 실행 계획 레벨에서 판단해야 합니다. 이유는 1장에서도 설명했던 것처럼, SQL 구문에는 어떻게 데이터를 검색 할지를 나타내는 접근 경로가 쓰여 있지 않기 때문입니다. 이를 알려면 실행 계획을 보는 수밖에 없습니다.
사실 이는 좋은 것이 아닙니다. “사용자가 데이터에 접근 경로라는 물리 레벨의 문제를 의식하지 않도록 하고 싶다”라는 것이 RDB와 SQL이 가진 컨셉이기 때문입니다. 하지만 아직 이런 뜻을 이루기에는 현재의 RDB와 SQL(그리고 하드웨어)는 역부족입니다. 따라서 은폐하고 있는 접근 경로를 엔지니어가 체크해줘야 합니다(* 저자주> 미래에 하드웨어와 DBMS가 충분히 발달하는 날이 온다면, 프로그래머가 이런 일을 하지 않아도 될 것입니다).
어쨌거나 UNION과 CASE의 쿼리를 구문적인 관점에서 비교하면 재미난 것이 있습니다. UNION을 사용한 분기는 SELECT ‘구문’을 기본 단위로 분기하고 있습니다. 구문을 기본 단위로 사용하고 있다는 점에서, 아직 절차 지향형의 발상을 벗어나지 못한 방법이라고 말할 수 있습니다. 반면 CASE 식을 사용한 분기는 문자 그대로 ‘식’을 바탕으로 하는 사고입니다. 이렇게 ‘구문’에서 ‘식’으로 사고를 변경하는 것이 SQL을 마스터하는 열쇠 중 하나입니다.
처음부터 그런 변경을 쉽게 실현하기는 힘듭니다. 요령을 하나 말하자면, 어떤 문제가 있을 때 스스로 “문제를 절차 지향형 언어로 해결한다면 어떤 IF 조건문을 사용해야 할까?”라고 사고할 때마다 “이것을 SQL의 CASE로는 어떻게 해결할 수 있지?”라는 것을 꾸준히 의식하는 것입니다. 이것만으로도 큰 도움이 될 것입니다.

DB 성능 최적화를 위한 SQL 실전 가이드 ▲ 『SQL 레벨업』
TAG :
이전 글 : PHP 개론

최신 콘텐츠